Adam의 문제점을 극복하는 새로운 optimizer인 AdamP를 제안하는 논문으로, Naver AI Lab & Naver Clova에서 ICLR 2021에 발표하였다.
Paper: https://arxiv.org/pdf/2006.08217.pdf
Project page: https://clovaai.github.io/AdamP/
Code: https://github.com/clovaai/adamp
1. Adam의 문제점
요약: Adam을 비롯한 momentum-based gradient descent optimzer들은 학습 도중 weight norm을 크게 증가시킨다.
그 원인은 다음과 같다.
대부분의 모델들에서 Batch normalization 등의 normalization 기법들을 사용해 weight를 scale-invariant하게 만든다. 따라서 weight들의 크기는 모델에 영향을 미치지 않게 된다.
따라서 모델에 영향을 미치는 값은, weight들을 l2-norm으로 나눈 값이다. 이들을 effective weight $\hat w=\frac{w}{||w||_2}$이라고 하자.
그러나 실제 optimization이 일어나는 공간은 effective weight이 있는 공간이 아니라, 원래의 weight가 놓여있는 nominal space이다.
이러한 이유로 effective step size와 실제 nominal step size 간에 차이가 발생한다. 아래 그림에서 $w_t$가 $w_{t+1}$으로 업데이트 되면, 실제 모델에 영향을 미치는 effective step은 주황색으로 표시된 부분과 같다.

Nominal step size와 effective step size는 약 $\frac{1}{||w_{t+1}||_2}$만큼 차이가 나게 된다.

일반적인 gradient descent (GD) 알고리즘을 사용하면 학습 도중 weight norm이 증가하는 현상이 발생하는데, (Lemma 2.1) 따라서 effective step size $\Delta \hat w_t$가 자연스럽게 줄어들게 되며 안정적인 학습을 돕는다.

그러나 Momentum이 추가된 Adam과 같은 optimizer의 경우, weight norm이 더욱 빠르게 증가한다 (Lemma 2.2).

그 결과, 아래 그림과 같이, GD는 수렴속도가 느리지만 weight norm이 크게 증가하지 않는 한편,
GD + momentum은 업데이트 속도가 빠르지만 weight norm이 역시 매우 크게 증가하여 effective step size는 그리 크지 않은 것을 확인할 수 있다.

이로 인해 effective convergence의 속도가 매우 느려지거나, sub-optimal한 해답을 찾을 수 있다는 문제가 발생하게 된다.
2. Method (SGDP, AdamP)
위에서 Adam과 같은 momentum 기반 optimizer의 문제를 밝혀냈다. 학습과정에서 weight norm을 매우 크게 증가시키는 성향이 있기 때문에, effective convergence의 속도가 매우 느려지고, sub-optimal한 해답을 찾게 된다는 것이다.
본 논문에서는 이를 projection을 이용하여, weight norm의 증가를 막을 수 있는 optimization 방법을 소개한다. 이 방법은 effective space에서의 update direction은 건드리지 않고, effective step size만을 변경할 수 있는 방법이다.
간단히 말하면, 매 update에서 weight와 parallel한 radial component를 제거하는 아이디어이다.

Update vector을 기존의 방법으로 계산한 뒤 ($p_t$), weight vector와 parallel한 성분은 projection으로 제거한다 ($\Pi_{w_t}(p_t)$).
Weight vector와 parallel한 성분은 loss minimization에는 기여하지 않고, weight norm을 증가시키는 데에만 기여하기 때문이다.
이 때 하이퍼파라미터인 $\delta$는 scale-invariant한 weight를 detect하는 역할을 한다. 논문에서는 $\delta=0.1$로 설정했다고 한다.
3. Experiments
Image classificaiton, object detection, audio classification, language modeling 등 다양한 도메인과 모델에 대해 실험을 진행했다.
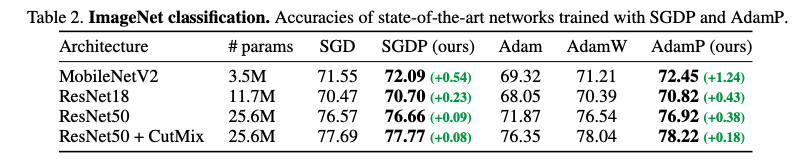
실험 1. Image classification - SGD, Adam과 비교했을 때 SGDP, AdamP가 항상 더 좋은 성능을 보였다.
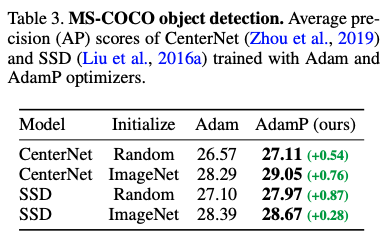
실험 2. Object detection - Adam보다 AdamP가 항상 더 좋은 성능을 보였다.
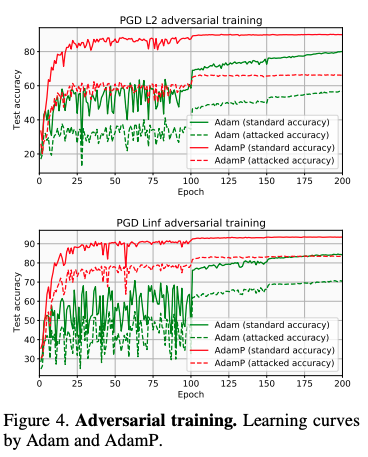
실험 3. Adversarial learning - model robustness를 평가하기 위해 실험을 진행했다. Adam보다 AdamP가 더 높은 robustness를 가진 것을 확인할 수 있다.