CutMix augmentation을 포인트클라우드 데이터에 적용한 논문이다. 두 포인트클라우드 데이터 간의 일대일 대응관계를 찾고, 이를 바탕으로 두 데이터를 섞는 두 가지 방법을 제안했다.
Paper: https://arxiv.org/pdf/2101.01461.pdf
Code: https://github.com/cuge1995/PointCutMix
Introduction
이미지 데이터에 대해 mixed sample data augmentation (MSDA)가 활발하게 사용되어 왔다. 대표적인 예시는 MixUp (Zhang et al., 2018)과 CutMix (Yun et al., 2019) 가 있다.

본 논문에서는 포인트클라우드 데이터에 대해 CutMix를 수행하는 PointCutMix를 제안한다.
Related Work
- 일반적으로 포인트클라우드 데이터에 대해 사용되던 augmentation으로는 random rotation, jittering, scaling 등이 있다. (Qi et al., 2017a;b)
- 이외에도 PointAugment (Li et al., 2020), PointMixUp (Chen et al., 2020) 등이 제안되었다.
- PointAugment의 경우는 adversarial training을 이용해 augmenter과 classifier network를 동시에 학습시키는 방법으로, 학습이 어렵다는 단점이 있다.
- PointMixUp은 말 그대로 포인트클라우드 데이터에 대해 MixUp augmentation을 수행하는 방법으로, local feature을 잃어버릴 수 있다는 단점이 있다.
Method
1. Optimal assignment of point clouds
MSDA를 수행하기 위해서는, 두 sample의 최소 단위에 대해 일대일 대응이 이루어질 수 있어야 한다.
최소 단위란, 이미지의 경우에는 픽셀에 해당하고, 포인트클라우드 데이터의 경우 하나의 포인트에 해당한다.
이미지의 경우 resize, crop 등을 이용하면 두 sample 간의 픽셀 간 일대일 대응을 간단히 정의할 수 있지만, 포인트클라우드는 해당 방법을 사용할 수 없다.
본 논문에서는 PointMixUp (Chen et al., 2020)과 MSN (Liu et al., 2020a)에서 사용한 방법을 따라, Earth Mover's Distance (EMD)를 위한 optimal assignment ϕ∗를 다음과 같이 정의한다.
ϕ∗=argminϕ∈Φ∑i||x1,i−x2,ϕ(i)||2
이는 두 점 사이 거리가 최소가 되게 하는 일대일 대응 함수를 찾는 것과 같다.
EMD는 ϕ∗를 이용해 다음과 같이 정의된다.
EMD=1N∑i||x1,i−x2,ϕ∗(i)||2
2. Mixing algorithm
PointCutMix의 목표는 서로 다른 두 개의 포인트클라우드 데이터 (x1,y1), (x2,y2)가 주어졌을 때 새로운 포인트클라우드 데이터 (˜x,˜y)를 찾는 것이다. 이때, x는 포인트클라우드, y는 classification 라벨을 의미한다.
- ˜x=B⋅x1+(IN−B)⋅˜x2
- ˜y=λy1+(1−λ)y2
이때 B는 b1,b2,...,bN을 대각성분으로 갖는 대각행렬로, bi는 i번째 포인트를 sampling할지를 결정하는 0또는 1의 값이다.
어떤 포인트를 sampling할지 정하는 방법은 두가지가 있는데, 이는 다음과 같다.
1. PointCutMix-R: x1에서 random하게 n개의 포인트를 sampling한다.
2. PoitnCutMix-K: centtral point를 하나 정하고, nearest neighbor을 이용해 주위의 n−1개의 점을 선택해 sampling한다.
λ는 sampling ratio를 의미하며, Beta(β,β) 분포에서 추출된다. β가 클수록 분포는 narrow해지며, 이는 모든 시행에 대해 비슷한 sampling ratio를 사용함을 의미한다.
서로 다른 sampling ratio λ값에 따른 결과는 다음과 같다.
Result
Comparison on different ρ and β values
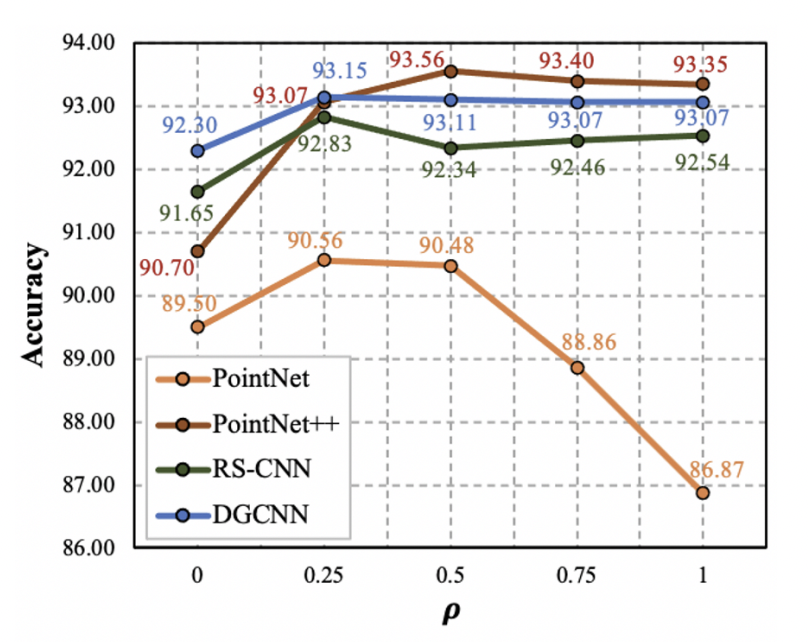
PointCutMix augmentation을 적용할 확률인 ρ와, sampling ratio의 편차를 조절하는 β 값을 바꿔가며 실험했다.
우선 ρ의 경우 0일 때 (augmentation을 사용하지 않음) 보다 항상 성능이 향상되고 그 값에 따른 차이가 별로 없는 데에 반해, PointNet만 ρ 값이 커질수록 성능이 급격히 하락했다. PointNet은 구조상 local한 feature을 포착하지 못하는데, 저자들은 이로 인해 PointNet 구조에는 PointCutMix가 효과가 없다고 판단, 이후의 실험에서 PointNet을 제외했다.
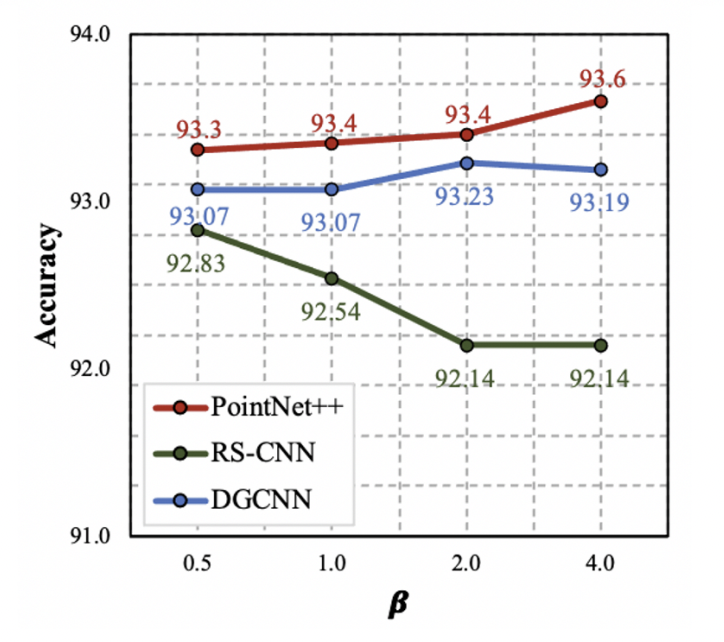
β의 경우도 값에 따른 성능 차이가 매우 적으나, RS-CNN은 매우 작은 β값을 선호하는 것을 확인할 수 있다. β값이 작을수록, 매 시행마다 비슷한 sampling ratio를 사용함을 의미한다.
Classification Result
ρ=1.0, β=1.0으로 설정했다.
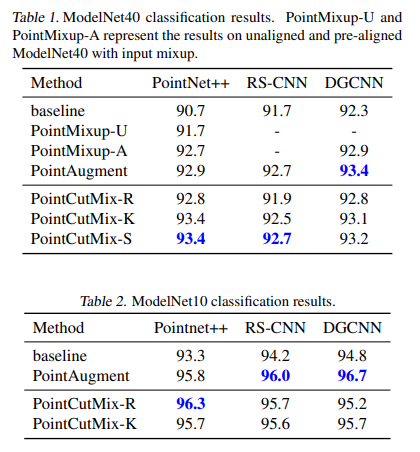
Baseline, PointMixUp, PointAugment 등과 비교했을 때 거의 항상 가장 높은 성능을 보였다.
Code (PyTorch Implementation)
코드는 Github에 공개된 official implementation을 일부 수정했다.
1. Optimal assignment of point clouds
두 Batch 데이터 간의 일대일대응 함수 부분이다. 이 함수 역시 Gradient backpropagation을 통해 함께 optimize된다.
#codes from https://github.com/cuge1995/PointCutMix/blob/main/emd/emd_module.py
class emdFunction(Function):
@staticmethod
def forward(ctx, xyz1, xyz2, eps, iters):
batchsize, n, _ = xyz1.size()
_, m, _ = xyz2.size()
assert(n == m)
assert(xyz1.size()[0] == xyz2.size()[0])
assert(n % 1024 == 0)
assert(batchsize <= 512)
xyz1 = xyz1.contiguous().float().cuda()
xyz2 = xyz2.contiguous().float().cuda()
dist = torch.zeros(batchsize, n, device='cuda').contiguous()
assignment = torch.zeros(batchsize, n, device='cuda', dtype=torch.int32).contiguous() - 1
assignment_inv = torch.zeros(batchsize, m, device='cuda', dtype=torch.int32).contiguous() - 1
price = torch.zeros(batchsize, m, device='cuda').contiguous()
bid = torch.zeros(batchsize, n, device='cuda', dtype=torch.int32).contiguous()
bid_increments = torch.zeros(batchsize, n, device='cuda').contiguous()
max_increments = torch.zeros(batchsize, m, device='cuda').contiguous()
unass_idx = torch.zeros(batchsize * n, device='cuda', dtype=torch.int32).contiguous()
max_idx = torch.zeros(batchsize * m, device='cuda', dtype=torch.int32).contiguous()
unass_cnt = torch.zeros(512, dtype=torch.int32, device='cuda').contiguous()
unass_cnt_sum = torch.zeros(512, dtype=torch.int32, device='cuda').contiguous()
cnt_tmp = torch.zeros(512, dtype=torch.int32, device='cuda').contiguous()
emd.forward(xyz1, xyz2, dist, assignment, price, assignment_inv, bid, bid_increments, max_increments, unass_idx, unass_cnt, unass_cnt_sum, cnt_tmp, max_idx, eps, iters)
ctx.save_for_backward(xyz1, xyz2, assignment)
return dist, assignment
@staticmethod
def backward(ctx, graddist, gradidx):
xyz1, xyz2, assignment = ctx.saved_tensors
graddist = graddist.contiguous()
gradxyz1 = torch.zeros(xyz1.size(), device='cuda').contiguous()
gradxyz2 = torch.zeros(xyz2.size(), device='cuda').contiguous()
emd.backward(xyz1, xyz2, gradxyz1, graddist, assignment)
return gradxyz1, gradxyz2, None, None
class emdModule(nn.Module):
def __init__(self):
super(emdModule, self).__init__()
def forward(self, input1, input2, eps, iters):
return emdFunction.apply(input1, input2, eps, iters)
2. Mixing algorithm (PointCutMix-R)
PointCutMix-R의 코드이다. Batch 데이터의 순서를 무작위로 섞은 후 위에서 정의한 emdModule을 이용해 원래 데이터와의 일대일대응을 계산한 후, 각각의 Batch 데이터를 일정 비율로 섞는다.
# codes are modified from https://github.com/cuge1995/PointCutMix/blob/main/train_pointcutmix_r.py#L252
for points, label in train_loader:
target = label
r = np.random.rand(1)
if r < cutmix_prob:
lam = np.random.beta(beta, beta)
B = points.size(0)
rand_index = torch.randperm(B) #shuffled index
target_a = target
target_b = target[rand_index] #shuffled label
point_a = points #[B, num_points, num_features]
point_b = points[rand_index] #shuffled points
point_c = points[rand_index]
remd = emdModule() #optimal assignment of point clouds
_, ind = remd(point_a, point_b, 0.005, 300) #assignment function [B, num_points]
for ass in range(B):
point_c[ass] = point_c[ass][ind[ass].long(), :] #rearrange pixels that correspond to point_a
int_lam = max(int(num_points * lam), 1) #number of points to sample
gamma = np.random.choice(num_points, int_lam, replace=False, p=None) #points to sample (Random sampling)
#cutmix
for i2 in range(B):
points[i2, gamma] = point_c[i2, gamma]
#adjust lambda to exactly match point ratio
lam = int_lam * 1.0 / num_points
#pred and calculate loss
pred = model(points)
loss = loss_f(pred, target_a.long()) * (1. - lam) + loss_f(pred, target_b.long()) * lam
else:
pred = model(points)
loss = loss_f(pred, target.long())