2021 ICCV에 Accept된 논문인 "Rethinking the Truly Unsupervised Image-to-Image Translation"을 정리한 글입니다. Naver CLOVA AI에서 작성된 논문입니다.
이전까지의 Unsupervised model (cycleGAN 등)은 사실 Semi-supervised 모델이라고 해야 한다고 얘기하며, Data collection(labeling)이 필요하지 않은 Truly unsupervised model인 TUNIT을 제안하고 있습니다.
논문 링크: https://arxiv.org/pdf/2006.06500
Official code: https://github.com/clovaai/tunit
1. Levels of Supervision in Generative Models

이전까지는 Generative model을 데이터의 종류에 따라 Supervisied와 Unsupervised 두 가지로 나눴습니다.
- Image와 Label이 쌍으로 존재하는 경우는 Supervised라고 합니다. Conditional GAN 등이 여기에 속하고, 학습이 비교적 쉽지만 이러한 데이터는 얻기 힘들다는 단점이 있습니다.
- Task에 따라, Image와 Label 데이터를 쌍으로 얻기 힘들거나 아예 불가능한 경우도 있습니다. 이 경우에는 각 Domain 별로 데이터를 수집합니다. 꼭 Image와 Label 데이터가 쌍으로 존재하지 않아도 됩니다. 이를 Unsupervised라고 하고, cycleGAN 등이 이에 속합니다.
본 논문에서는 Generative model의 Supervision의 정도를 세 가지로 분류합니다. 이전까지 Unsupervised라고 했던 것 역시 Domain 별로 데이터를 모으고, 라벨링을 해야 한다는 점에서 Semi-supervised라고 불러야 하고, 진정한 Unsupervised 모델은 이러한 데이터 라벨링 없이도 Image-to-image translation을 수행할 수 있어야 한다고 주장합니다.
Truly Unsupervised Learning
본 논문에서는, True unsupervised learning이란 각 데이터에 대한 라벨(Class)이 없는, 여러 Domain의 이미지들로 구성된 하나의 데이터셋에서 이미지를 생성해낼 수 있는 것이라고 정의합니다.

True unsupervised learning의 장점은 다음과 같습니다.
- 별도의 Data annotation을 하지 않아도 됩니다.
- 따라서, 이러한 라벨링 작업에서 오는 Noise를 방지할 수 있습니다.
- Semi-supervised model에 대한 강력한 Baseline을 제공할 수 있습니다.
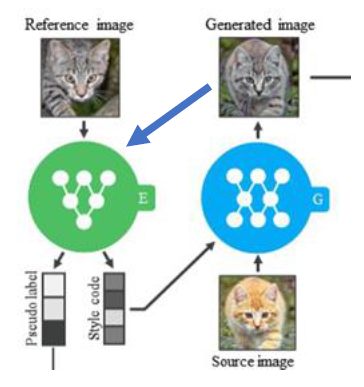
TUNIT Architecture
TUNIT은 두 가지의 구조, 세 가지의 Network로 구성되어 있습니다.

Guiding network는 Input image의 Domain(label)을 분류(Clustering)하고 Style code를 추출하는 역할을 합니다.
GAN은 Input image를 Target domain으로 변환하는 역할, 즉 Mapping function을 학습합니다.

Guiding network는 두 개의 Branch를 가진 하나의 Encoder로 구성되어 있습니다.
하나의 Branch($E_C$)에서는 Clustering 결과(Pseudo label)를 출력하고,
다른 하나의 Branch($E_S$)는 Style code를 담은 vector를 출력합니다.
Style code는 GAN의 Generator가 이미지를 변환하는 데에 사용되고,
Pseudo label은 Discriminator가 변환된 이미지의 Real/Fake를 판단하는 데에 사용됩니다.
Training Guiding Network
Guiding network의 학습 방법에 대해 먼저 알아보겠습니다.
앞서 말한대로, Guiding network는 동일한 Encoder를 공유하는 두 개의 Branch로 구성되어 있습니다.
Pseudo label을 생성하는 $E_C$는 Mutual information (MI)를 기반으로 하는 Clustering 기법을 이용하고,
Style code를 생성하는 $E_S$는 Contrastive loss를 이용합니다.
Training $E_C$ : use differentiable clustering method based on mutual information (MI) maximization

학습 방법
- Input image $x$와, 이를 Random하게 Augmentation한 Image $x^+$를 이용합니다.
- 이들을 $E_C$에 input으로 준 결과를 각각 $p$, $p+$라고 하며, 이는 각 K개의 domain 각각에 속할 확률을 담은 vector, 즉 Pseudo label입니다. ($p=E_C(x)$)
- $p$, $p+$의 Mutual information이 최대가 되는 방향으로 Encoder를 학습시킵니다.
- Loss function의 수식은 다음과 같습니다.
(Maximize) $L_{MI} = I(p,p^+) = I(P) = \sum^K_{i=1}\sum^K_{j=1}P_{ij}ln\frac{P_{ij}}{P_iP_j}$
즉, $x$와 $x+$의 Pseudo label의 Mutual information이 최대가 되게 하는 것입니다.
Mutual information은 두 variable의 상호의존성을 측정한 것으로, 위키백과에서는 다음과 같이 설명하고 있습니다.
Mutual information is therefore the reduction in uncertainty about variable X , or the expected reduction in the number of yes/no questions needed to guess X after observing Y .
Mutual information에 대한 보다 자세한 설명은 아래 링크를 참고 바랍니다.
http://www.scholarpedia.org/article/Mutual_information
간단히 말하자면, Mutual information을 최대가 되게 함으로써, Encoder은 두 Image $x$와 $x+$가 같은 label에 속하도록 합니다.
본 논문에서는 Clustering의 한 방법으로써 Mutual information maximization을 사용하였으나, 다른 Clustering 방법을 사용해도 된다고 얘기합니다.
Training $E_S$ : use contrastive loss

학습 방법
- MoCo라는 모델에서 가져온 방법입니다.
- $E_C$를 학습시킬 때와 마찬가지로, randomly augmented sample을 이용합니다.
- Input image $x$를 Randomly augment한 Image $x+$을 Positive sample로 이용하고, 다른 Image들을 Negative sample로 이용합니다 ($x_n^-$).
- 1개의 Positive sample $x+$과 N개의 Negative sample $x_n^-$, 총 N+1개의 sample을 $E_S$ 에 넣은 Output을 이용해 N+1 way classification을 수행합니다.
- 즉, $s=E_S(x)$라고 할 때, Positive pair의 style vector ($s$, $s^+$) 간의 유사도를 최대화하고, Negative pair의 style vector ($s$, $s^-$) 간의 유사도를 최소화하는 방식입니다.
- Loss function의 수식은 다음과 같습니다.
(Minimize) $L^E_{style} = -log\frac{exp(s\cdot s^+ / \tau)}{\sum^N_{i=0}exp(s \cdot s^-_i / \tau)}$
Training Guiding Network
정리하자면,
- Guiding Network는 동일한 Encoder를 공유하며, Pseudo label을 생성하는 $E_C$와, Style code를 생성하는 $E_S$ 두 가지 Branch로 이루어져 있으며,
- 각각의 Loss function $L_{MI}$와 $L_{style}$을 이용해 각 Branch를 학습시킵니다.
그러나 각 Branch를 따로따로 학습시키는 것이 아니고, 두 Loss function을 합쳐 함께 (Jointly) 학습을 진행합니다.
이렇게 두 Task를 한 번에 학습시켰을 때의 장점은 다음과 같습니다.
- Clustering은 Style code 학습 과정에서 학습하는 Rich representation을 활용할 수 있습니다.
- Style code는 Clustering 학습 과정에서 학습하는 Domain-specific nature과, 같은 Domain에 속하는 데이터들의 유사성을 활용할 수 있습니다.
이러한 이유로 Joint training을 이용하였고, Guiding network의 Loss function은 다음과 같게 됩니다.
(Minimize) $-L_{MI} + L_{style}$
실제로 $L_{MI}$를 이용해 $E_C$를 학습시켰을 때보다, $L_{style}$까지 활용해 Joint training을 했을 때 생성된 Pseudo label의 정확도가 높았다고 합니다.

Training Generative Network (GAN)
Generative Network (GAN)은 3가지의 Loss function을 이용해 학습시켰습니다.
1) Realistic한 Image를 생성하기 위한 Adversarial Loss와,
2) Style code를 잘 보존하기 위한 Style Contrastive Loss,
3) cycleGAN의 identity loss와 유사한 Image Reconstruction Loss
세 가지를 이용했습니다.
Adversarial Loss

일반적인 GAN Loss와 동일합니다.
차이점은, Generator에 Reference image의 style code $\widetilde{s}$가 input으로 들어간다는 것입니다.
Generator은 Style code $\widetilde{s}$를 반영하면서 Input image $x$를 Target domain $\widetilde{y}$로 변환하는 것이 목표입니다.
수식은 다음과 같습니다.

참고로, Style code를 적용하는 방법은 AdaIN을 이용했습니다.
Generator 구조에 5개의 AdaIN layer가 포함되어 있는데,
1) Style vector을 MLP에 통과시켜 각 AdaIN에 사용할 Parameter들을 뽑아낸 다음,
2) 이를 각 AdaIN layer에 적용시키는 방법으로 Input image에 Style을 입혔습니다.

Style Contrastive Loss
Style Code를 잘 보존하기 위한 추가적인 Loss입니다.
Generator을 통해 생성된 Image의 Style code $s'=E_S(G(x, \widetilde{s}))$와, Reference image의 Style code $\widetilde{s}$간의 Contrastive Loss를 계산합니다.
이는 생성된 Image가 Input으로 주어진 Style code를 얼마나 잘 보존하고 있는지를 계산합니다.
수식은 아래와 같습니다.
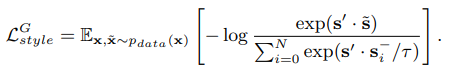
Image Reconstruction Loss

Reference image를 Source image와 동일하게 주었을 때, 생성된 Image가 원본과 얼마나 동일한지를 계산하는 Loss입니다.
이는 Source Image의 Style code를 이용한 것이기 때문에, 네트워크가 잘 학습되어 있다면 원본과 동일한 Image가 나오는 것이 이상적입니다.
CycleGAN의 Identity Loss와 유사하다고 느꼈습니다.
수식은 다음과 같습니다.

Train All Network Jointly
앞서, Guiding network를 학습할 때 두 Loss function들을 한번에 학습한다고 했습니다.
GAN의 학습도 모든 Loss function을 한 번에 학습시키고,
이 뿐 아니라 Guiding network와 GAN의 학습 역시 동시에 진행됩니다.
다시 말해, 모든 학습이 end-to-end로 한 번에 진행되는 것입니다.

이는 Guiding network에서 Clustering과 Style code가 서로의 학습에 도움을 주었던 것처럼,
GAN과 Guiding network 역시 서로의 학습 과정에 도움을 준다고 합니다.
Experiments & Results
실험은 Supervised Translation에서 SOTA 모델인 FUNIT을 Unsupervised setting으로 바꾼 것과 비교했습니다. 이외에도 다양한 실험을 진행했지만, 일부 결과만 간략히 소개하도록 하겠습니다.
자세한 실험내용과 결과는 논문을 참고하시면 될 것 같습니다.
Labeled Dataset에 대한 실험


Unlabeled Dataset에 대한 실험

Conclusion
논문에서 주장하는 Contribution은 여러 가지가 있지만, 그 중에서도 가장 중요한 것은 Unsupervised image-to-image translation을 재정의하고, 이러한 Task를 수행하는 End-to-end model을 제시했다는 점인 것 같습니다.
본 게시물에서는 최대한 간략하게 논문을 정리했지만, 보다 디테일한 부분이나 구현 관련 내용들은 논문과 공식 깃헙 코드를 참고하시면 될 것 같습니다.