CVPR 2019에 발표된 Dual Attention Network for Scene Segmentation이다. Scene segmentation에 attention을 적용하여 성능을 향상시켰다.
Code: https://github.com/junfu1115/DANet
Abstract
- self-attention을 이용해 scene segmentation task에서 rich contextual dependency를 포착는 것을 목표로 한다.
- 기존의 attention 모델들은 multi-scale feature을 결합하는 방법들을 사용했다면, DANet은 끝 단에 두 종류의 attention module (position attention, channel attention)을 추가하는 방식이다.
- Position attention: 각각의 position에 대해 모든 position의 feature들을 weighted sum으로 결합한다.
- Channel attention: 각각의 channel map에 대해 모든 channel map의 feature들을 weighted sum으로 결합한다.
- 두 attention module로부터 나온 feature map을 sum fusion 방식으로 결합하여 최종 output을 결정한다.
Introduction
효과적인 scene segmentation을 하기 위해서는 1) 혼동되기 쉬운 category들을 잘 구별할 수 있어야 하며, 2) 서로 다른 위치에 나타나는 같은 category의 물체들을 같은 category로 분류할 수 있어야 한다. 이를 위해서 feature representation의 pixel-level에서의 discriminative ability를 향상시켜야 한다.
기존의 연구들은 FCN을 이용해 context fusion을 하는 방법이나, LSTM을 이용하는 방법 등이 있었는데, 전자의 경우 global view에서의 relationship을 포착하지 못했고, 후자의 경우 LSTM의 long-term memorization에 크게 의존한다는 단점이 있었다.
DANet은 각 pixel간의 spatial dependency를 포착하는 position attention과, 각 channel간의 channel dependency를 포착하는 channel attention을 이용하여 문제를 해결한다.
Method

전반적인 구조는 위 그림과 같다. Convolution 연산은 local receptive field를 갖기 때문에, 같은 label을 갖고 있는 멀리 떨어진 pixel에 해당하는 feature들의 값이 서로 달라질 수 있으며, 이는 intra-class inconsistency를 야기할 수 있다. (쉽게 말해 같은 class에 속하는 물체라도, local한 영역만 보는 convolution 연산의 특성으로 인해, 멀리 떨어져 있으면 서로 다른 feature representation을 가지게 될 수 있다.)
이 문제를 해결하기 위해, attention을 통해 global contextual information을 얻을 것이다. 이 방법을 통해 long-range contextual information을 결합할 수 있다.
Backbone(ResNet)에서 나온 feature들은 두 개의 parallel한 attention module로 들어간다. 각 attention module은 다음과 같이 진행된다.
1) Conv layer을 통해 feature dimension reduction을 진행한다. (회색)
2) 각 pixel 간의 spatial relationship 혹은 각 channel 간의 relationship을 표현하는 attention matrix를 생성한다.
3) Attention matrix와 original feature을 곱한다.
4) 위의 multiplied resulting matrix와 original feature을 더한다.
이후 각각 구한 attention output들을 sum fusion을 이용해 합친다.
각 attention module에 대한 자세한 설명은 다음에서 이어진다.
Position Attention Module

- Input feature A (C, H, W)에 대해,
- Conv layer을 통해 새로운 feature map B와 C (C, H, W)를 만든다.
- 이들을 flatten하여 (C, N)으로 reshape한 후 (N=H*W),
- softmax(C'@B)를 통해 spatial attention map S (N, N)을 만든다.
$s_{ji}=\frac{\exp(B_i\cdot C_j)}{\sum_i^N\exp(B_i\cdot C_j)}$
- 또한, A로부터 conv. layer을 통해 또 하나의 새로운 feature map D (C, H, W) 를 만들고 flatten하여 (C, N) 으로 reshape한다.
- 이번엔 D@S’를 한 후 (C, N) 이를 다시 (C, H, W)로 reshape한다.
- 여기에 scale parameter $\alpha$ (learnable)를 곱하고 원래의 A와 element-wise sum을 해서 final output E (C, H, W)를 만든다.
$E_j=\alpha\sum_i^N(s_{ji}D_i)+A_j$
- 결국, 각 position의 값은 모든 position과 original의 weighted sum이라고 볼 수 있다.
- 이는 intra-class compact와 semantic consistency를 개선시킬 수 있다.
Channel Attention Module

- High level feature의 각 channel map은 class-specific response를 담고 있다고 볼 수 있다. Channel map 간의 interdependency를 조사함으로써, interdependent한 feature map들을 강조할 수 있다.
- 전반적인 구조는 Position attention module과 같으나, 처음 conv layer을 통해 feature map을 추출하는 과정이 없다.
- A를 (C, N)으로 reshape한 후, softmax(A@A’)를 통해 channel attention map X (C, C)를 만든다.
$x_{ji}=\frac{\exp(A_i\cdot A_j)}{\sum_i^C\exp(A_i\cdot A_j)}$
- 이후 X’@A를 한 후 (C, N) 다시 (C, H, W)로 reshape한다.
- scale parameter $\beta$ (learnable)를 곱하고 원래의 A와 element-wise sum을 해서 final output E(C, H, W)를 만든다.
$E_j=\beta\sum_i^C(X_{ji}A_i)+A_j$
- 결국, 각 channel의 값은 모든 channel과 original의 weighted sum이라고 볼 수 있다.
- 이는 feature discriminability를 개선하는 데 도움을 준다.
- Channel attention module은 두 channel간의 relationship을 유지하기 위해 conv. layer을 통한 추가적인 feature embedding을 하지 않았다.
- 다른 channel attention 방법들과의 차이점은, global pooling이나 encoding layer을 거치지 않아, channel correlation을 계산할 때 spatial information을 사용했다는 점.
Sum fusion
- Conv3x3 + sum을 통해 feature fusion을 진행한다. 이 때 concatenation을 이용하지 않은 이유는 GPU memory를 아끼기 위함이다.
- 이후 마지막 conv1x1를 통해 final prediction을 생성한다.
코드는 다음과 같다.

Experiments
데이터셋으로는 Cityscapes, PASCAL VOC 2012, PASCAL Context dataset, COCO stuff를 이용했다.
Cityscapes를 이용해 다양한 ablation study를 진행했다.

Position attention module (PAM)과 channel attention module (CAM)을 바꿔가며 실험했다. 결과는 각 module을 썼을 때 성능이 올라가고, 함께 썼을 때 가장 좋다.

Figure 4, 5에서는 이에 대한 visualization을 제공한다.
- Figure 4: Position attention을 사용했을 때, 디테일과 물체의 boundary가 더 선명해짐을 확인할 수 있다 (pole, sidewalk). 이를 통해 position attention은 detail의 discrimination 성능을 향상시킴을 알 수 있다..
- Figure 5: Channel attention을 사용했을 때, 잘못 분류되던 class가 correct된 것을 확인할 수 있다 (bus). 이를 통해 channel attention은 context information을 포착함을 알 수 있다.
각 attention module에서 계산된 attention 값들에 대한 visualization도 진행했다.

- Column 2, 3: 빨간 점으로 표시된 pixel에 대한 position attention map이다. 같은 category에 속하는 부분들이 강조된 것을 확인할 수 있다. 이로써 position attention은 clear semantic similarity와 long-range relationship을 포착함을 알 수 있다.
- Column 4, 5: 11번째와 4번째 channel의 attention map이다. 각 channel의 attention map이 각각 하나의 class를 나타내고 있음을 확인할 수 있다. 이로써 channel attention을 통해 특정 semantic의 응답이 더 noticable해졌음을 알 수 있다.
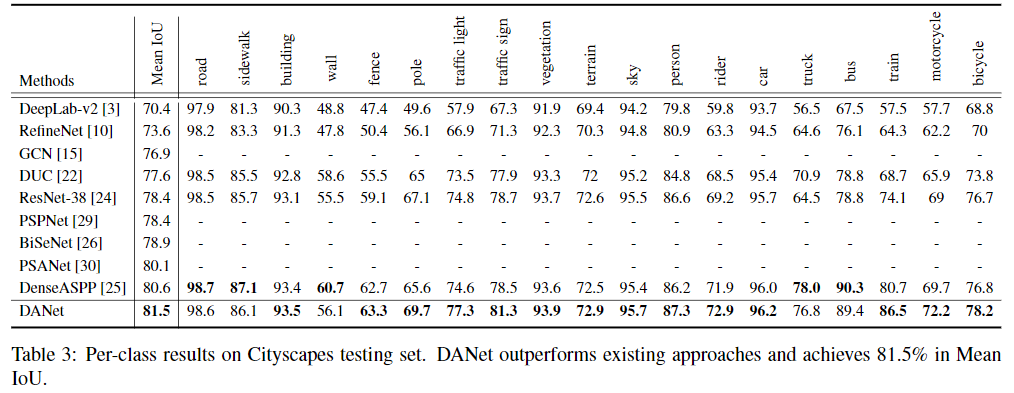
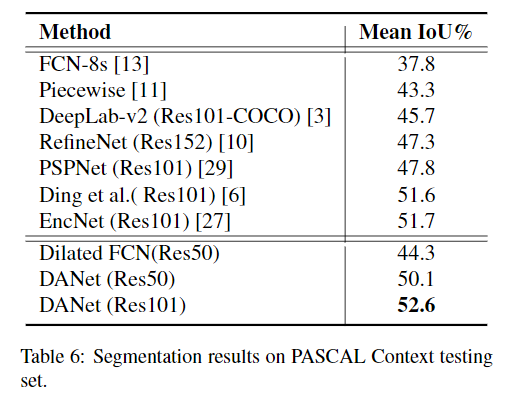
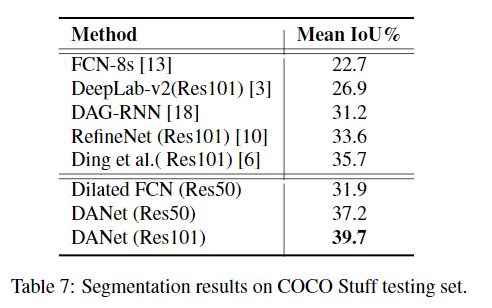
각 데이터셋에 대한 SOTA model들과의 비교는 다음과 같다.