ICLR2020에 발표된 논문인
Deep Double Descent: Where Bigger Models and More Data Hurt
를 바탕으로 정리한 글입니다.
다양한 Deep Learning task에서 발견되는 Double-descent라는 현상을 Model complexity 관점에서 해석하고,
어떤 경우에서는 Model complexity나 Train epoch를 증가시키는 것이 성능을 하락시킬 수도 있다고 주장합니다.
Classical Statistics vs. Modern Neural Networks
1) Classical Statistics: Bias-variance trade-off에 따르면, Model complexity가 일정 수준 이상 커지면 Overfitting이 발생해 오히려 성능이 하락합니다.

2) Modern Neural Networks: 대부분의 경우 오히려 모델이 클수록 더 좋은 성능을 보입니다. (Bigger models are better)
3) Training time에 관해서도 의견이 분분합니다. 어떤 경우에서는 Early stopping을 사용하는 것이 더 성능이 높고, 어떤 경우에서는 Epoch을 크게 할수록 좋다고 얘기하고 있죠.
왜 상황마다 이렇게 다른 결과가 발생할까요?
Two Regimes of Deep Learning Setting
본 논문에서는 딥러닝 모델의 Setting에 따라 두 가지 Regime이 존재한다고 말합니다.

1. Under-parameterized regime (Classical Regime): Sample의 수에 비해 모델의 Complexity가 작은 경우.
이 경우, 모델의 Complexity에 대한 Test error의 함수는 Classical bias/variance tradeoff를 따르는 U모양 형태를 나타냅니다.
2. Over-parameterized regime (Modern Regime): 모델의 Complexity가 충분히 커서 Train error가 0에 수렴하는 경우.
이 경우 모델의 Complexity를 증가시킬수록 Test error은 감소합니다.
위와 달리, Modern intuition인 "Bigger models are better"을 따르는 경우입니다.
단순히 말해, Model Complexity에 따른 Test error이 감소->증가->감소의 형태를 띄게 되는데요,
이러한 현상을 2018년 Belkin 등이 "Double descent"라고 명명하고, 다양한 ML 및 DL task에서 나타남을 보였습니다.
본 논문에서는
- Effective Model Complexity (EMC)라는 Complexity measurement를 도입하여 Double descent에 대한 정의를 세웠고,
- 실험을 통해 실제로 매우 다양한 setting에서 Double descent가 발생함을 보였습니다.
Effective Model Complexity (EMC)
Effective Model Complexity (EMC)는 Model Complexity를 나타내는 척도입니다. 정의는 다음과 같습니다.

여기서 S는 n개의 Sample을 갖고 있는 Train dataset입니다.
간단히 말하자면, EMC는 모델의 Train error이 0에 가깝게 수렴하게 만드는 데이터의 개수를 의미합니다.
EMC가 클수록 Model Complexity가 높음을 의미합니다.
이 EMC를 이용하여 Generalized Double Descent hypothesis를 다음과 같이 정의합니다.
1) EMC가 Dataset 크기보다 충분히 작은 경우 : Under-parameterized regime
이 때 EMC를 증가시키면 Test error은 줄어든다.
2) EMC가 Dataset 크기보다 충분히 큰 경우 : Over-parameterized regime
이 때 EMC를 증가시키면 Test error은 줄어든다.
3) EMC가 Dataset 크기와 비슷한 경우 : Critically parameterized regime
이 때 EMC를 증가시키면 Test error은 줄어들거나 늘어난다.
위의 그래프에 각 구간을 다시 표시하면 아래와 같습니다.
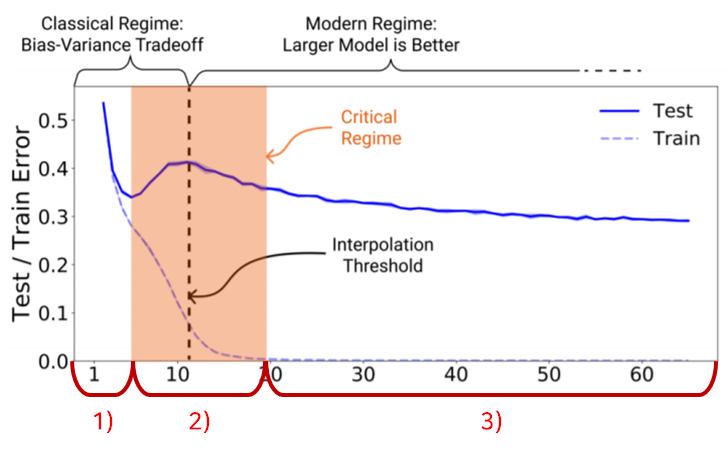
이와 같이 EMC라는 개념을 도입해 Double descent를 설명했습니다.
따라서 Interpolation threshold(EMC=n인 지점)을 기준으로,
- Critical interval 외부에서는 Model complexity를 늘리는 것이 성능에 도움이 되나
- Critical interval 내부에서는 Model complexity를 늘리는 것이 오히려 성능을 떨어트릴 수 있다
라고 얘기하고 있습니다.
하지만 Critical interval의 너비가 어느 정도인지는 Data distribution과 Training procedure의 종류 등에 따라 각각 다른데, 이에 대해서는 아직 정확하게 알지 못한다고 합니다. 따라서 이 hypothesis가 informal하다고 얘기하고 있어요.
Experiments
정말 다양한 실험을 통해 위의 hypothesis를 검증했습니다. 몇 가지의 실험 결과만 소개하도록 하겠습니다. 논문에서 자세한 실험 내용과 더 많은 결과를 확인하실 수 있습니다.
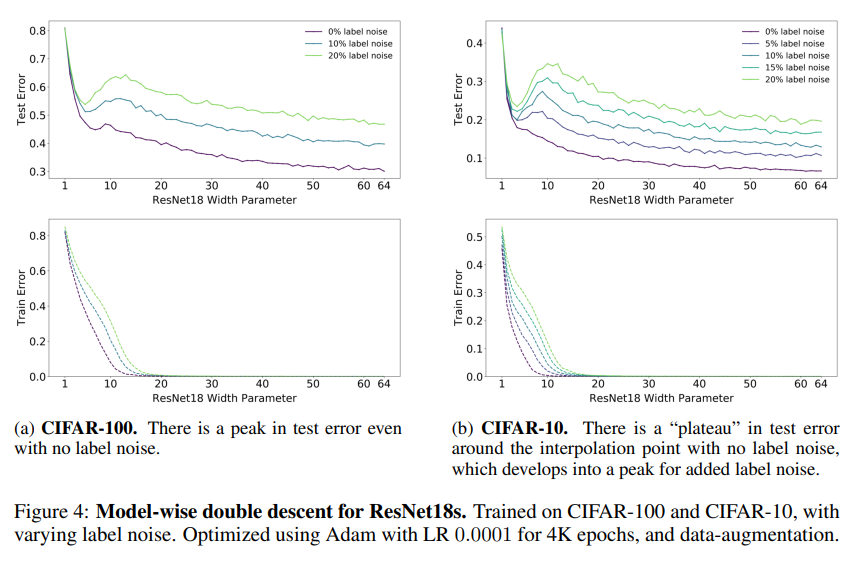
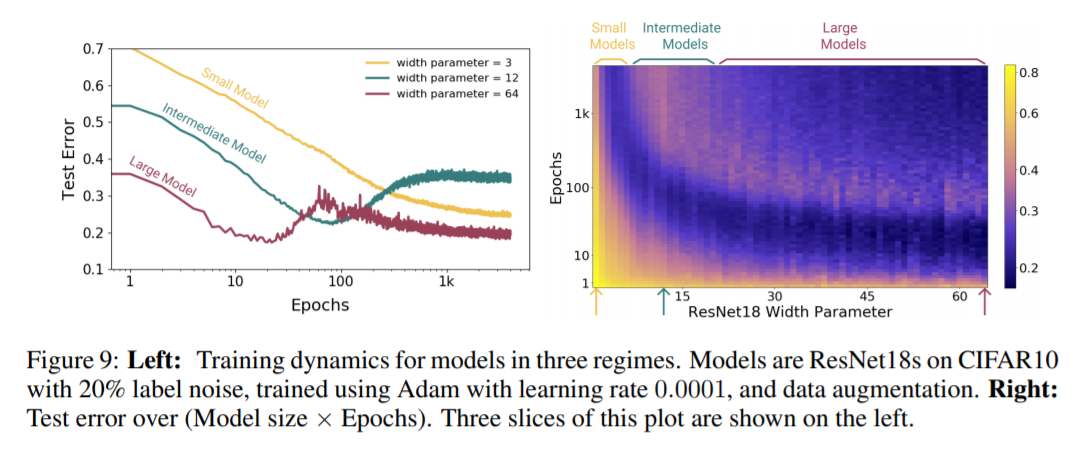
- Model-wise Double Descent: 다양한 Datsaet, model architecture, optimizer, number of train samples, training procedures에 대해 실험을 진행해 model size에 따른 double descent 현상을 관찰하고, test error peak이 interpolation threshold에서 나타나는 것을 확인하였습니다. Bigger models are worse
- Epoch-wise Double Descent: model size 뿐 아니라 epoch에 대해서도 double descent 현상을 관찰하였습니다. Training longer can correct overfitting