NVIDIA와 Baidu에서 연구하고 ICLR 2018에 발표된 논문인
Mixed Precision Training을 바탕으로 정리한 글입니다.
딥러닝 학습 과정에서 Mixed Precision을 이용하여 GPU resource를 효율적으로 사용할 수 있는 방법입니다.
(NVIDIA 블로그 정리글: developer.nvidia.com/blog/mixed-precision-training-deep-neural-networks/)
Floating Point Format
실수를 컴퓨터로 나타내는 방법에 고정소수점(Fixed Pint) 방식과 부동소수점(Floating Point) 방식이 존재합니다.
(부동소수점 방식은 떠돌이 소수점 방식이라고도 한다고 합니다. 귀엽네요)
고정소수점 방식은 정수부와 소수부를 담을 비트의 수를 고정해서 사용하는 방식.
정확하고 연산이 빠르지만 표현 가능한 범위가 부동소수점 방식에 비해 좁습니다.
부동소수점 방식은 표현하고자 하는 수를 정규화하여 가수부(exponent)와 지수부(fraction/mantissa)를 따로 저장하는 방식입니다.
예를 들자면 다음과 같습니다.
5.6875를 2진법으로 나타내면 101.1011
이를 1.011011 * 2^2로 나타내는 것을 정규화라고 합니다. (정수부에 한 자리만 남기는 것)
이 때 1.011011을 가수부, 2의 지수인 2를 정수부라고 하고,
부동소수점 방식은 이 가수부와 정수부를 각각 저장하는 방식입니다.

부동소수점 방식은 IEEE754 표준이 가장 널리 쓰이고 있는데, 그 종류는 다음과 같습니다.
- FP32 (Single Precision, 단정밀도)
- FP64 (Double Precision)
- FP128 (Quadruple Precision)
- FP16 (Half Precision)
FP 뒤의 숫자는 몇 bit를 이용하는지를 의미합니다. FP32는 32bit를 이용하여 실수를 저장하는 것.
당연히 이용하는 비트 수가 많을수록 더 높은 정밀도(Precision)로 실수를 저장할 수 있습니다.
(FP64는 FP32의 두 배의 정밀도를 갖는다는 뜻에서 Double Precision이라고 부르는 것이겟죠?)
현대 딥러닝 학습 과정에서는 Single Precision(FP32) 포맷을 사용합니다.
(weight 저장, gradient 계산 등)
하지만 Single Precision(FP32) 방식이 아닌, Half Precision(FP16) 방식으로 학습을 진행한다면,
한정된 GPU의 resource를 아낄 수 있지 않을까요?
Mixed Precision
Half Precision(FP16) 방식을 이용해 학습을 진행하면 당연히 저장공간도 아끼고, 연산 속도도 빨라집니다.
하지만 Half Precision 방식은 Single Precision 방식보다 정밀도가 현저히 떨어지죠.

따라서 gradient가 너무 큰 경우, 혹은 너무 작은 경우 오차가 발생하게 되고, 이 오차는 누적되어 결국 학습이 잘 진행되지 않습니다.

위 그림에서 검정색 선은 FP32를 이용해 학습시킨 결과, 회색 선은 FP16을 이용해 학습시킨 결과입니다.
Y 축은 training loss인데, FP16으로 학습시키는 경우 loss가 줄어들다가 수렴하지 못하고 다시 커지는 것을 확인할 수 있죠.

위 그림은 실제로 FP32를 이용해 네트워크를 학습시키고, 임의의 gradient 값들을 sampling 한 결과입니다.
빨간 선 왼쪽의 gradient들은 FP16에서 표현 불가능한 정밀도의 값들이기 때문에, FP16에서는 0으로 표현되고, 이러한 오차들이 누적되어 모델 학습에 어려움이 발생합니다.
본 논문에서 제안한 Mixed Precision Training은 FP32와 FP16을 함께 사용하여 이를 극복합니다.
= Mixed Precision
Implementation
방법은 굉장히 간단합니다. 실제로 gradient 값들이 매우 작은 값에 몰려 있어서 FP16으로 casting 시 0이 되어 버립니다.
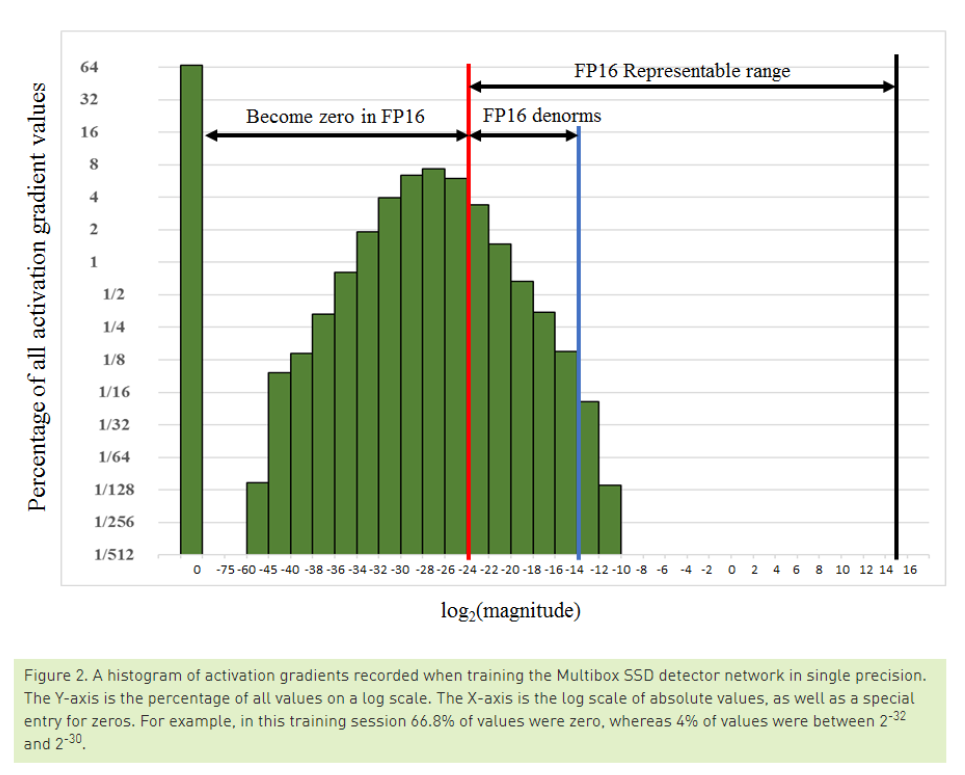
즉, FP16의 표현 가능 범위 밖에 gradient가 분포해서 생긴 문제인데,
그렇다면 단순히 Scaling을 통해 gradient를 FP16의 표현 가능 범위 안으로 이동시켜 주면 되지 않을까요?
좀 더 자세히 나타내면 다음과 같습니다.
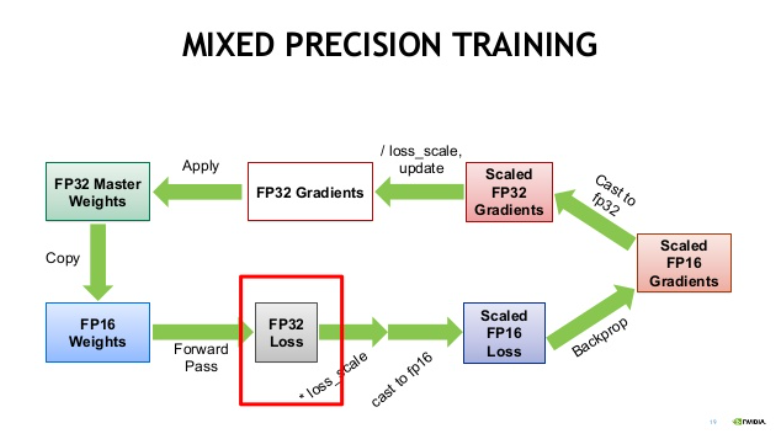
Step 1. FP32 weight에 대한 FP16 copy weight을 만든다.
(이 FP16 copy weight은 forward pass, backward pass에 이용된다.)
Step 2. FP16 copy weight을 이용해 forward pass를 진행한다.
Step 3. forward pass로 계산된 FP16 prediction 값을 FP32로 casting한다.
Step 4. FP32 prediction을 이용해 FP32 loss를 계산하고, 여기에 scaling factor S를 곱한다.
Step 5. scaled FP32 loss를 FP16으로 casting한다.
Step 6. scaled FP16 loss를 이용하여 backward propagation을 진행하고, gradient를 계산한다.
Step 7. FP16 gradient를 FP32로 casting한고, 이를 scaling factor S로 다시 나눈다.
(chain rule에 의해 모든 gradient는 같은 크기로 scaling된 상태임)
Step 8. FP32 gradient를 이용해 FP32 weight를 update한다.
정리하자면, FP32 weight은 계속 저장해 두고,
FP16 copy weight를 만들어 이를 이용해 forward/backward pass를 진행하는 것입니다.
FP16 copy weight으로 얻은 gradient를 이용해 FP32 weight를 update합니다.
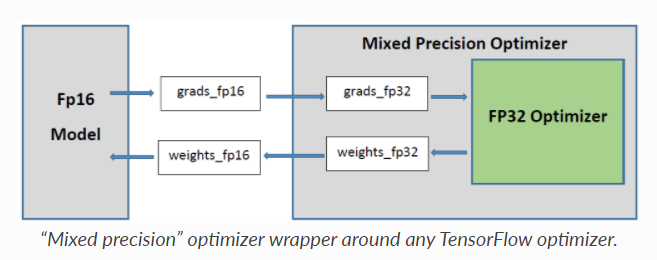
* 이 때 Scaling Factor은 어떻게 정할까요?
논문에서는 단순히 경험적인 값을 선택하거나,
gradient의 통계화가 가능한 경우 gradient의 maximum absolute value가 65,504(FP16이 표현가능한 최대값)가 되도록 맞춰 주면 된다고 합니다.
Scaling factor이 크다고 해서 나쁜 점은 없지만, overflow가 일어나지 않도록 주의해야 합니다!
Experiment & Result
Classification, detection 등 간단한 task부터 시작해서 GAN 까지 아주 다양한 실험을 진행했습니다. (Method가 너무 단순했기 때문일까요?)
몇 가지 결과를 보여드리겠습니다.
* Baseline: FP32 / MP: Mixed Precision(FP32+FP16)
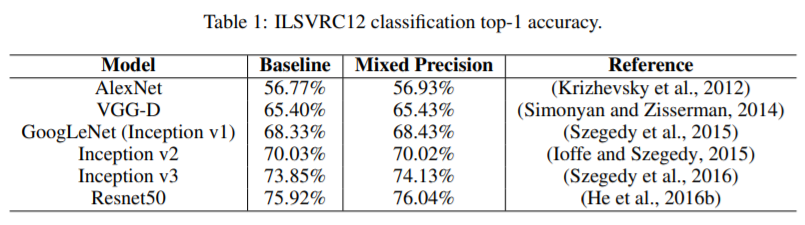


Mixed Precision에서 성능이 오히려 오른 것도 있고, 전반적으로 FP32에 뒤지지 않는 성능을 보여준 것 같죠?
논문에서 자세한 실험 setting과 더 많은 결과를 확인하실 수 있습니다.
PyTorch Implementation
PyTorch에서 공식적으로 Mixed Precision Training을 지원합니다.
Automatic Mixed Precision(AMP) 라는 이름으로, 몇 줄의 코드만 추가하면 손쉽게 사용 가능합니다.
공식 문서: pytorch.org/docs/stable/amp.html
Automatic Mixed Precision package - torch.cuda.amp — PyTorch 1.7.0 documentation
The following lists describe the behavior of eligible ops in autocast-enabled regions. These ops always go through autocasting whether they are invoked as part of a torch.nn.Module, as a function, or as a torch.Tensor method. If functions are exposed in mu
pytorch.org
Github에 잘 정리된 코드가 있어 가져왔습니다.
출처: github.com/hoya012/automatic-mixed-precision-tutorials-pytorch
일반적인 학습 코드
for batch_idx, (inputs, labels) in enumerate(data_loader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
AMP를 적용한 코드
""" define loss scaler for automatic mixed precision """
# Creates a GradScaler once at the beginning of training.
scaler = torch.cuda.amp.GradScaler()
for batch_idx, (inputs, labels) in enumerate(data_loader):
optimizer.zero_grad()
with torch.cuda.amp.autocast():
# Casts operations to mixed precision
outputs = model(inputs)
loss = criterion(outputs, labels)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(self.optimizer)
# Updates the scale for next iteration
scaler.update()
학습을 시작하기 전 scaler을 선언해주고,amp.autocast()를 이용하여 casting 과정을 거치며 foward pass를 진행합니다.backward pass, optimization, weight update 등의 과정이 모두 scaler을 통해 진행되는 형태인 것 같죠?
위 Github에서 실제로 Torch의 AMP를 이용해 실험을 진행해 보셨어요.
GTX 1080 Ti와 RTX 2080 Ti를 이용하여 실험을 진행해 보셨다고 합니다.
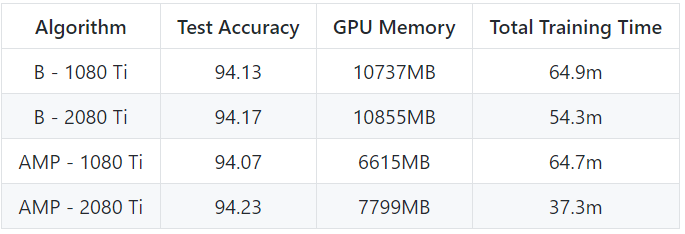
1080 Ti를 이용했을 때, 2080 Ti를 이용했을 때 모두 GPU 메모리는 당연 적게 사용한 것을 볼 수 있고,
Training Time은 2080 Ti를 이용했을 때에만 줄어들었네요.
Test Accuracy는 두 경우 모두 줄어들지 않아 성능저하는 없었음을 알 수 있습니다.

RTX 2080 Ti은 Tensor Core이 탑재되어 FP16의 계산이 획기적으로 빠르다고 합니다.
때문에 Tensor Core이 탑재된 GPU를 사용했을 때 Torch AMP가 시간 측면에서도 빛을 발할 것 같네요.
(Tensor Core에 대한 자세한 설명은 www.nvidia.com/ko-kr/data-center/tensor-cores/)
Tensor Core은 TF32라는 자체 정밀도를 이용해서 FP32보다 최대 20배까지 가속이 가능하다고 하는데
위 실험 결과를 보면 FP32를 이용한 Baseline에서는 속도 면에서 큰 차이가 없네요.. 왜일까요?
Conclusion
GPU의 resource를 아낄 수 있고, 학습 시간까지 단축시킬 수 있는 Mixed Precision Training에 대해 리뷰해 보았습니다.
PyTorch에서 매우 간단하게 구현도 가능해서, 정말 안 쓸 이유가 없을 것처럼 느껴지네요.
FP32의 정밀도는 유지하면서 FP16을 이용해 저장공간을 아끼는 방법이었는데,
그렇다면 FP32를 이용해서 FP64의 정밀도를 구현하는 방법도 가능하지 않을까요?
정밀도가 중요한 task에서는 한번쯤 시도해 보고 싶습니다.