SimCLR와 함께 가장 유명한 contrastive learning-based self-supervised learning 논문이다. CVPR 2020에서 발표된 논문이고, Kaiming He가 저자로 참여하였다.
GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722 - GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
github.com
I. Introduction
Contrastive learning을 이용한 self-supervised learning은 dynamic dictionary를 만드는 것으로 해석될 수 있다. (Section II)
Dictionary의 "key" (token)들은 encoder network로 encoding된 데이터 sample들로 구성된다.
Self-supervised learning은 encoding된 "query"에 대한 dictionary look-up으로 진행된다. Query와 매칭되는 key와는 비슷하게, 나머지 key와는 다르게 되도록 하는 encoder를 학습시키는 것을 목표로 한다.
MoCo는 이 dictionary를 queue로 구현하여 batch size를 늘리고, momentum update를 통해 key encoder를 일관되게 유지한다. (Section III)
II. Contrastive Learning
본 논문에서는 contrastive learning을 dictionary look-up task를 수행하는 encoder를 학습시키는 것으로 해석한다.

Encoded query $q$와, encoded key의 dictionary $\{k_0, k_1, k_2, ...\}$가 있다고 하자. 이때 dictionary에서 $q$와 매칭되는 key $k_+$가 하나 있다고 하면, contrastive loss는 $q$가 $k_+$와 유사도가 높고, 나머지 key와는 유사도가 낮을 때 작은 값을 갖는 함수라고 볼 수 있다.
InfoNCE는 이 유사도를 dot product로 계산하는 contrastive loss의 일종이다.
$\mathcal L_q=-\log\frac{\exp(q\cdot k_+/\tau)}{\sum^K\exp(q\cdot k_i/\tau)}$
이는 $q$를 $k_+$로 분류하고자 하는 (K+1)-way softmax-based classifier에 대한 log loss로도 해석될 수 있다. Contrastive loss는 이 외에도 여러가지가 있지만, 본 논문에서는 InfoNCE를 이용한다.
Contrastive learning이 self-supervised learning을 위해 사용될 때, query와 key는 query network $f_q$와 key network $f_k$를 통해 다음과 같이 얻어진다.
- $q=f_q(x^q)$
- $k=f_k(x^k)$

이 때 두 network는 동일할 수도 있고, 일부분만을 공유할 수도 있고, 서로 다르게 설정할 수도 있다.
III. MoCo
MoCo는 다음 두 가지를 고려하여 고안된 모델이다.
1) Dictionary의 크기를 최대한 크게 하면, negative sample이 다양해져 좋은 representation을 학습할 수 있다.
2) Dictionary key를 생성하는 encoder는 최대한 일정하게 유지되어야 학습이 안정될 수 있다.

Dictionary as a queue
MoCo는 dictionary를 queue를 이용해 구현했다. 매 mini-batch마다, encoded key들은 dictionary에 enqueue되고, dictionary가 꽉 차면 오래된 순서로 key들이 dequeue된다. 이를 통해 이전 mini-batch의 key들을 재사용할 수 있게 되고, 따라서 dictionary 크기와 mini-batch 크기를 분리할 수 있다. 즉, mini-batch size보다 더 큰 dictionary를 사용할 수 있게 되고, 더 많은 pair을 비교할 수 있게 된다. 이 과정은 이 블로그에 그림으로 잘 설명되어 있으니 참고하는 것을 추천한다.
[CVPR 2020] Momentum Contrast for Unsupervised Visual Representation Learning (MoCo) 핵심 리뷰
내용 요약 저자들은 기존의 Contrastive Learning을 Dynamic Dictionary System이라고 정의합니다. 그리고 이 시스템을 개선하기 위한 두 가지 포인트로 Dictionary를 더 크게 만드는 것과 업데이트 방식을 개선
ffighting.tistory.com
Momentum update
Dictionary로 queue를 이용하면, key encoder을 backpropagation을 통해 업데이트할 수 없다. 따라서 저자들은 처음에 단순하게 query encoder을 매번 복사하여 key encoder로 사용하는 방법을 시도했다고 한다. 그러나 이 경우 학습이 잘 진행되지 않았는데, 이는 key encoder이 매번 급격히 변화하면 dictionary의 key들의 representation에 일관성이 없어지기 때문이라고 한다.
대신 momentum update를 이용해 key encoder을 업데이트하기로 했는데, 이는 모든 파라미터에 대해 다음과 같이 업데이트를 진행하는 것이다.
$\theta_k \leftarrow m\theta_k+(1-m)\theta_q$
이는 query encoder와 key encoder의 파라미터를 적절하게 섞어 주는 것이라고 볼 수 있다.
논문의 실험에서는, momentum $m$을 크게 사용하는 것(e.g. $m$=0.999)이 성능이 좋았다고 한다. 즉, 기존 값을 최대한 유지하여 key encoder의 일관성을 유지하는 방향으로 설정한 것이다.
Pseudocode
위에서 설명한 MoCo의 pseudocode는 다음과 같다.

IV. Results
다른 unsupervised learning method와 ImageNet classification 성능을 비교했다.

또, ImageNet supervised pre-training과 비교하여, PASCAL VOC, COCO dataset에서의 성능을 비교했다.
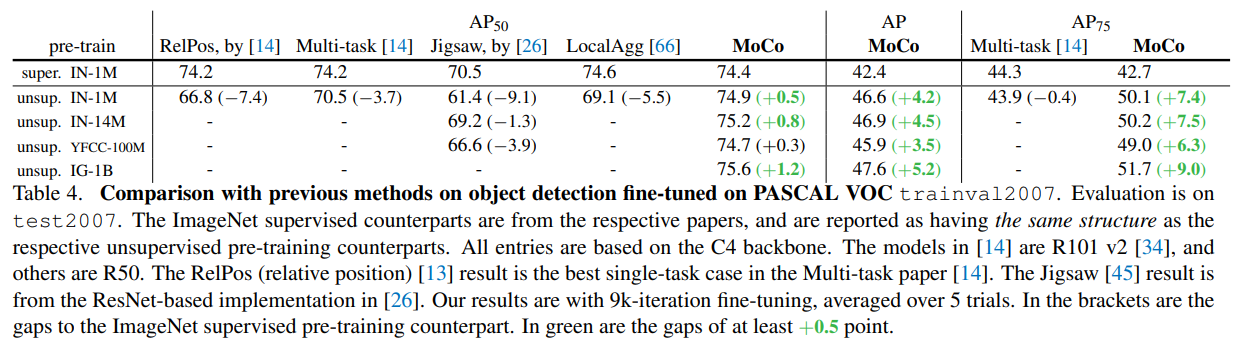

Supervised learning method보다도 더 좋은 representation을 학습했음을 확인할 수 있다.