Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy (CSUR 2021) 을 바탕으로, 중요한 GAN 모델들을 정리해 보고자 합니다. 논문에는 더 다양한 모델들이 소개되어 있으나, 그 중 일부만 정리하였습니다. GAN에 대해 어느 정도 배경지식이 있는 분들을 위한 글이며, 본 논문에서는 각 모델에 대한 간단한 요약만 포함하고 있어, 추가로 조사한 내용을 포함시켰으며 참고할 만한 외부 글들은 링크를 걸어놓았습니다.
목차는 다음과 같습니다.
- Introduction
- Brief introduction to GAN
- Architecture-variant GAN - BiGAN, CGAN, InfoGAN, DCGAN, BEGAN
- Loss-variant GAN - WGAN, WGAN-GP, LSGAN
1. Introduction
최근 많은 GAN 연구들은 두 가지 objective에 집중하고 있습니다.
(1) 학습의 개선
(2) Real-world application
학습 과정을 개선시킴으로써, GAN의 성능에 다음과 같은 방향으로 기여할 수 있습니다.
(1) 생성된 이미지의 diversity의 개선 (mode diversity)
(2) 생성된 이미지의 quality의 개선
(3) 학습의 안정화 (e.g., vanishing gradient issue for generator)
이렇게 GAN의 성능을 개선하기 위한 다양한 GAN-variant들이 제안되어 왔고, 이를 두 가지로 분류할 수 있습니다.
(1) 모델 구조를 개선하는 방법 - Architecture-variant
(2) Loss의 관점에서 접근하는 방법 - Loss-variant
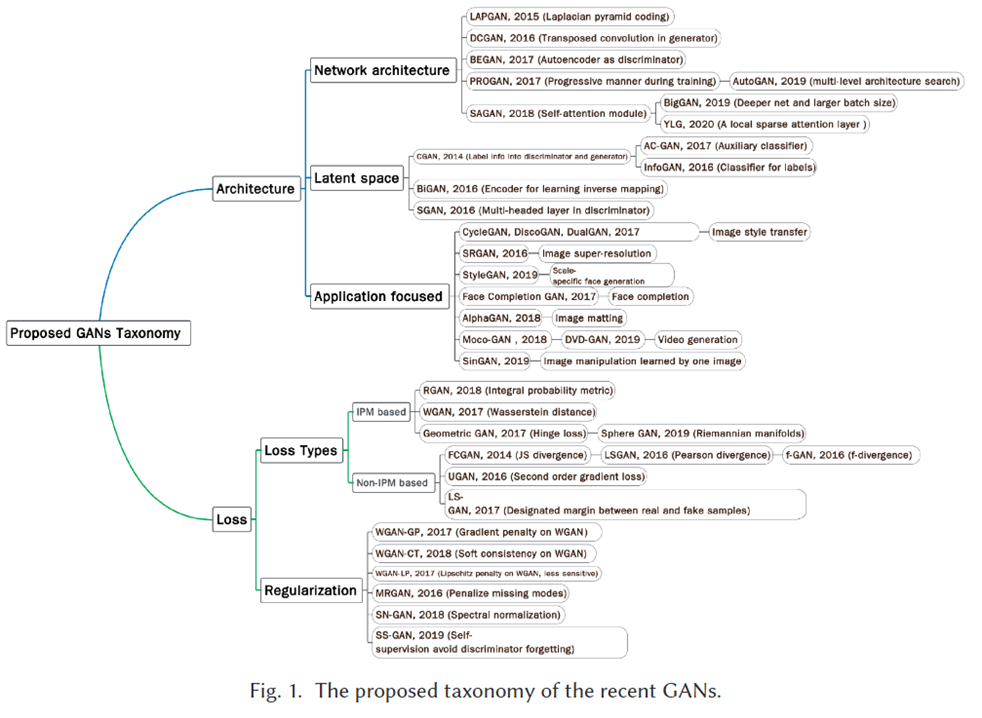
본 survery 논문은 위에서 제시한 세 가지의 성능 향상 (image diversity와 quality의 개선, 학습의 안정화) 에 초점을 둔 GAN-variant들을 소개합니다.
GAN application에 초점을 둔 review는 다음 두 논문을 추천합니다.
[1] Saifuddin Hitawala. 2018. Comparative Study on Generative Adversarial Networks. arXiv:1801.04271(2). Retrieved from https://arxiv.org/abs/1801.04271.
[2] Yongjun Hong, Uiwon Hwang, Jaeyoon Yoo, and Sungroh Yoon. 2019. How generative adversarial networks and their variants work: An overview. ACM Comput. Surv.52, 1 (2019), 10.
2. Brief introduction to GAN
GAN variant를 소개하기 전에, GAN에 대해 간단히 소개하고 넘어가겠습니다.

GAN의 구조를 흔히 '경찰'과 '도둑'에 비유하곤 합니다. 도둑(Generator)이 위조지폐를 생성하면, 경찰(Discriminator)은 위조지폐와 진짜 지폐를 보고 어느 것이 진짜/가짜인지를 가려내는 역할을 합니다.
Discriminator은 진짜와 가짜를 더욱 잘 판별하게끔, Generator은 가짜를 더욱 진짜에 가깝게 만들게끔 하는 방향으로 학습이 진행됩니다.
Generator와 Discriminator이 서로 경쟁하면서 학습하기 때문에 Generative Adversarial Network라는 이름이 붙게 되었습니다.

위 그림이 GAN의 기본 구조입니다. Generator은 random noise를 input으로 받아 fake image를 만들어내고, Discriminator은 generator에서 생성된 fake image와 training set에서의 real image를 input으로 받아 이것이 진짜인지 가짜인지 판별합니다.
GAN의 최종 목적은 진짜 데이터 분포인 $p_r$과 최대한 근사하는 분포 $p_g$를 학습하는 것으로 볼 수 있습니다. 결국 분포를 근사하는 것이 GAN의 목표이며, objective는 다음과 같이 나타냅니다.
$\min_G\max_D\mathbb{E}_{x\sim p_r}\log[D(x)]+\mathbb{E}_{z\sim p_z}\log[1-D(G(z))]$
다른 deep generative models (DGM)과 비교했을 때 GAN의 장점은 다음과 같습니다.
(1) 다른 DGM 보다 더 나은 output 생성.
(2) 어떤 generator network도 backbone으로 이용할 수 있음.
(3) latent variable의 크기에 대한 제약이 없음.
3. Architecture-variant GAN
Bi-Directional GAN (BiGAN) (ICLR 2017)

- 기존의 GAN 구조에 더해 Inverse mapping을 학습하는 GAN입니다. Inverse mapping이란 image를 latent space로 다시 projection하는 것을 의미합니다.
- BiGAN은 기존의 GAN 구조에 inverse mapping을 수행하는 Encoder을 추가했습니다. 따라서 BiGAN은 Enoder E, generator G, discriminator D 세 가지 네트워크로 구성되어 있습니다.
- 학습과정은 다음과 같습니다.
- G는 random noise z를 input으로 받아 generated image G(z)를 생성합니다.
- E는 training data x를 input으로 받아 latent vector E(x)를 생성합니다.
- D는 (E(x), x)와 (z, G(z)) pair을 input으로 받아 어떤 것이 진짜/가짜 pair인지를 판별합니다.
- Discriminator을 완전히 속이기 위해서는 encoder과 generator이 완전히 서로 반대의 mapping을 학습해야 한다는 증명이 논문에 포함되어 있습니다.
Conditional GAN (CGAN) (arXiv 2014)

- Generator과 Discriminator에 추가 정보 y를 condition으로 제공해 줄 수 있는 GAN입니다. 이 때 추가 정보 y는 class label이 될 수도 있고, 다른 modal data가 될 수도 있습니다.
- 예를 들어, MNIST dataset의 경우 각 숫자의 종류를 y로 주어, 원하는 종류의 숫자를 생성하도록 조건으로 줄 수 있습니다.
- Objective: $\min_G\max_D\mathbb{E}_{x\sim p_r}\log[D(x|y)]+\mathbb{E}_{z\sim p_z}\log[1-D(G(z|y))]$
- GAN objective에 conditioning y만 추가되었습니다.
- 손글씨 생성 외에도 CGAN으로 수행할 수 있는 task로는 Yahoo Flickr Create Common 100M (YFCC 100M) (labeled image data + user-tag) 데이터셋을 이용한 Auto image tagging가 있습니다.

- Train process:
- image의 feature을 generator에 condition으로 주어 word embedding vector을 생성합니다.
- image에 대응하는 tag들을 word embedding을 통해 vector로 변환시키고, generator에서 생성된 word embedding vector과 함께 discriminator에 전달합니다. 이 때 image feature을 condition으로 주어 discriminator이 진짜/가짜 tag embedding을 판별하도록 합니다.
- Evaluation process:
- Generator은 image feature과 random noise를 input으로 받아 output vector을 출력합니다.
- 하지만 이 vector들은 continuous한 값이기 때문에 word embedding 값들과 정확히 일치하지는 않습니다.
- Cosine similarity를 이용해, generator이 생성한 vector과 가장 유사한 word embedding 값을 가지는 word들을 구하고, 이들 중 Top 10 most common words를 최종 tag prediction으로 사용합니다.
InfoGAN (NeurIPS 2016)

- 정보이론을 바탕으로 하고 있습니다.
- Interpretable representation (disentangle representation)을 학습하는 것을 목표로 합니다.
- 우리가 GAN을 학습하면, generator은 어떤 vector을 input으로 받아 이미지를 생성하게 됩니다. 우리는 그 vector의 의미를 해석할 수 없으나, input vector 값에 따라 생성되는 이미지가 달라지므로 이 vector 안에 이미지의 각 특성에 대한 정보가 담겨져 있음은 확실하나, 그 정보들이 많이 entangle되어 있어 사람이 해석하기 쉽지 않습니다.
- 따라서 아래 그림처럼 각 vector의 element가 이미지의 하나의 특징을 의미하고 있으면 좋을 텐데, 예를 들어 MNIST datset이라고 했을 때 input vector의 첫 번째 element는 숫자 종류를 의미하고, 두 번째는 숫자의 기울기, 세 번째는 숫자의 너비 등을 의미하는 값이 되도록 만드는 것을 disentangle representation이라고 합니다.

https://www.slideshare.net/ssuser06e0c5/infogan-interpretable-representation-learning-by-information-maximizing-generative-adversarial-nets-72268213
- InfoGAN에서는 generator에 code라고 하는 vector c(그림에는 y로 표현되어 있음)을 추가로 input으로 주어 구현했습니다. code는 CGAN의 condition과 같은 역할을 하며, code의 각 element가 생성된 이미지의 각각의 특징을 의미한다고 볼 수 있습니다.
- MNIST dataset을 이용해 학습한 결과입니다. code는 길이 3의 vector이며, 첫 번째 element $c_1$은 각 숫자의 종류를 의미하고, 두 번째 element $c_2$는 숫자의 기울기, 세 번째 element $c_3$는 숫자의 너비를 표현합니다. 오른쪽으로 갈수록 해당하는 code element 값을 조금씩 변화하여 생성한 image인데, 실제로 각 특징들이 조금씩, 매끄럽게 변화하는 것을 확인할 수 있습니다.

- InfoGAN은 이를 mutual information maximization을 이용해 해결했습니다.
- InfoGAN은 CGAN에 classifier Q를 추가한 구조입니다. Q는 generator에서 생성된 image G(z|c)를 input으로 받아 code c를 다시 복원하는 것이 목표입니다.
- G와 Q의 조합은 autoencoder로 볼 수 있는데, 결국 c가 주어졌을 때 G가 이를 embedding하고, c와의 cross entropy를 최소화하는 c'를 생성하는 것이 Q이기 때문입니다.
- Q와 D는 마지막 FC layer을 제외하고 모든 weight를 공유합니다. 이는 파라미터 수를 줄이는 효과도 있을 뿐더러, discriminator이 진짜/가짜를 판별하는 능력에 더해 c라는 정보를 복원하는 능력까지 갖게 만들어, 학습을 보다 용이하게 합니다.
- Objective: $\min_G\max_DV(D,G)-\lambda I(c, G(z,c))$
- $V(D, G)$: objective of CGAN
- $I(\cdot)$: mutual information
- mutual information (MI)는 상호 정보량을 의미합니다. MI를 최대화시킴으로써, G는 code의 정보를 최대한 보존하면서 이미지를 생성하게 됩니다.
- 이는 결국 다음과 같습니다. (증명은 생략)
- $\min_G\max_DV(D,G)-\lambda I(G, Q)$
- InfoGAN에 대한 보다 자세한 설명은 다음 링크를 참고 바랍니다.
- 참고1: 유재준님 블로그 (https://jaejunyoo.blogspot.com/2017/03/infogan-1.html#more)
- 참고2: 오창대님 블로그 (https://velog.io/@changdaeoh/InfoGAN-review)
Boundary Equilibrium GAN (BEGAN) (arXiv 2017)

- Discriminator로 진짜/가짜를 구별하는 binary classifier 대신, autoencoder를 사용합니다.
- 기존 GAN 모델들이 data distribution을 직접 맞춘 것과 달리, BEGAN은 Wasserstein distance를 통해 autoencoder loss distribution을 맞추는 것이라고 볼 수 있습니다.
- 이는 Generator가 "autoencoder이 쉽게 reconstruct할 수 있는" 이미지를 생성하도록 합니다.
- 이는 학습초반, Discriminator가 쉽게 Generator을 이기는 것을 방지해 줍니다. 학습초반에는 Discriminator가 real data distribution을 아직 완벽히 익히지 못했기 때문입니다.
- Loss distribution을 익힌다는 것이 쉽게 이해가 가지 않을 수 있는데, Real/fake image와, autoencoder을 통해 reconstruct된 image 간의 difference를 생각해보면 쉽습니다. autoencoder가 input image를 reconstruct할 때 어떤 부분을, 얼만큼 틀리는지를 비슷하게 한다고 생각하면 될 듯 합니다.

https://t-lab.tistory.com/27 - Discriminator로 autoencoder을 사용하는 것에 대한 이유는 유재준님 블로그에서 쉽게 설명되어 있어 첨부합니다.

https://jaejunyoo.blogspot.com/2017/04/began-boundary-equilibrium-gan-1.html - D objective: $\min\mathbb{E}[\mathcal{L}(x)]-\mathbb{E}[\mathcal{L}(G(z))]$
- G objective: $\min\mathbb{E}[\mathcal{L}(G(z))]$
- 추가로, Equilibrium을 위한 hyperparameter $\gamma=\frac{\mathbb{E}[\mathcal{L}(G(z))]}{\mathbb{E}[\mathcal{L}(x)]}$를 도입합니다.
- 이는 G loss와 D loss의 balance를 맞추기 위한 것으로, 모델의 diversity와 생성된 image의 quality 사이에서 균형을 맞춰 주어 model collapse를 방지해줍니다.
- BEGAN에 대한 보다 자세한 설명은 다음 링크를 참고 바랍니다.
-
참고2: 티랩 블로그 (https://t-lab.tistory.com/27)
Deep Convolutional GAN (DCGAN) (ICLR 2016)

- 처음으로 generator 구조에 transpose convolution을 사용한 논문이며, 이후 이것이 GAN generator에서 mainstay가 되었습니다.
- High-resolution과 stable training을 위한 critical modification을 제시한 논문입니다.

4. Loss-variant GAN
- GAN의 불안정성은 global optimum criterion으로부터 나옵니다.
- Global optimum은 any G에 대해 D가 optimum을 달성했을 때에 성립됩니다. 즉 loss에 대한 D의 derivative가 0일 때 이므로
- $-\frac{p_r(x)}{D(x)}+\frac{p_g(x)}{1-D(x)}=0\rightarrow D^*(x)=\frac{p_r(x)}{p_r(x)+p_g(x)}$
- 이를 G의 loss에 대입하면
- $\mathcal{L}_G=\mathbb{E}_{x\sim p_r}\log\frac{p_r(x)}{\frac12[p_r(x)+p_g(x)]}+\mathbb{E}_{x\sim p_g}\log\frac{p_g(x)}{\frac12[p_r(x)+p_g(x)]}-2\cdot\log2$
- $=2\cdot JS(p_r||p_g)-2\cdot\log2$
- 이는 두 distribution의 JS divergence에 대한 minimization이 됩니다.
- GAN의 불안정성은 D가 G를 너무 쉽게 이기는 데에서 기인하는데, 이것이 바로 JS divergence때문입니다.
- GAN이 objective는 $p_g$를 $p_r$로 이동시키는 것인데, JS divergence는 두 distribution 간 overlap이 없는 경우 constanct (log2=0.693)의 값을 갖습니다. 즉 아래 그림에서 왼쪽과 가운데의 경우 JS divergence가 같습니다.

- Global optimum은 any G에 대해 D가 optimum을 달성했을 때에 성립됩니다. 즉 loss에 대한 D의 derivative가 0일 때 이므로
- Vanishing gradient 문제를 피하기 위해, G의 objective로 $-\mathbb{E}_{x\sim p_g}\log[D(x)]$를 최소화하는 방법도 제안되었으나, 이는 또다른 문제인 mode dropping을 야기합니다.
- 이 경우 G의 objective는 다음과 같이 변합니다.
- $-\mathbb{E}_{x\sim p_g}\log[D^*(x)]=KL(p_g||p_r)-2\cdot JS(p_r||p_g)+2\cdot\log2+\mathbb{E}_{x\sim p_x}\log[D^*(x)]$
- 이 loss는 앞의 두 term (KL, JS)에만 영향을 받는데, 이 중 KL에 dominate됩니다. (JS는 [0, log2] bounded이기 때문)
- 이 첫 번째 term은 reverse KL divergence (maximize KL divergence) 문제로, 이는 KL divergence와는 매우 다른 양상을 보입니다.

- 오른쪽이 reverse KL divergence인데, 이 경우 한 쪽 mode에만 optimize하는 mode collapse 현상이 발생합니다.
- 이 경우 G의 objective는 다음과 같이 변합니다.
- 따라서, GAN의 ultimate problem은 loss function design에서 나오는 것이고, loss function을 redesign함으로써 이 문제를 해결할 수 있습니다.
Wasserstein GAN (WGAN) (ICML 2017)
- Earth mover (EM) or Wasserstein-1 distance를 loss measure로 사용합니다.
- EM은 KL이나 JS와 달리, overlap이 없는 distribution 간의 거리도 반영할 수 있으며, 따라서 meaningful gradient를 전파할 수 있어 Train stabilize에 큰 역할을 합니다.
- Loss for D: $\max_{w\sim\mathcal{W}}\mathbb{E}_{x_{p_r}}[f_w(x)]-\mathbb{E}_{z\sim p_z}[f_w(G(z))]$
- 이때 $f_w$는 특정한 constraint와 함께 Discriminator을 이용해 근사할 수 있습니다.
- Loss for G: $-\min_{G}\mathbb{E}_{z\sim p_z}[f_w(G(z))]$
- WGAN과 일반 GAN의 가장 큰 차이점은 Discriminator로, 이는 Wasserstein distance를 fitting하는데 사용되므로 classification이 아닌 regression task를 수행하게 됩니다.
WGAN-GP (NeurIPS 2017)
- WGAN이 학습의 안정화에 큰 효과를 보였으나, deeper model에서 잘 일반화 되지는 않았습니다.
- WGAN에서는 립시츠 조건을 만족시키기 위하여 [-0.01, 0.01]의 범위로 parameter clipping을 했는데, 이로 인해 WGAN의 대부분의 parameter들이 -0.01, 0.01의 값을 가지는 것이 관측되었습니다.

- WGAN-GP는 parameter clipping 대신 Discriminator gradient penalty (GP)를 도입하여 이를 해결합니다.
- Optimal discriminator은 gradient가 1인 특징을 이용해 loss에 다음과 같이 regularization term을 추가합니다.
- $\mathcal{L}_D=\mathbb{E}_{x_{x_g\sim p_g}}[D(x_g)]-\mathbb{E}_{x_{x_r\sim p_r}}[D(x_r)] + \lambda\mathbb{E}_{\hat x\sim p_{\hat x}}[(||\nabla_{\hat{x}}D(\hat{x})||_2-1)^2]$'
- 이전까지는 얕은 network에서만 학습이 가능했는데 (DCGAN은 4-layer), WGAN-GP를 사용하여 ResNet-101을 backbone으로 학습하는데 성공했다고 합니다. WGAN-GP는 이후 PROGAN, BigGAN 등 large-scale image generation GAN 연구에 큰 영향을 끼쳤습니다.
Least Square GAN (LSGAN) (ICCV 2017)
- LSGAN은 Generator의 Vanishing gradient 문제를 Discriminator의 decision boundary의 관점으로 바라봅니다.
- Decision boundary에서 매우 떨어져 있는 sample들은 매우 작은 loss를 갖게 되어, Generator이 잘 update되지 않습니다.
- 이에 sigmoid cross entropy 대신 MSE를 사용합니다.
- Loss for D: $\min_D\mathcal{L}_D=\frac12\mathbb{E}_{x\sim p_r}[(D(x)-b)^2]+\frac12\mathbb{E}_{z\sim p_z}[(D(G(z))-a)^2]$
- Loss for G: $\min_G\mathcal{L}_G=\frac12\mathbb{E}_{z\sim p_z}[(D(G(z))-c)^2]$
- a: label for generated samples
- b: label for real samples
- c: hyperparameter that G wants D to recognize the generated samples as the real samples by mistake
- ex) a=-1, b=1, c=0
- WGAN과 유사하게 Discriminator은 regression task를 수행하고, 역시 sigmoid 함수는 제외됩니다.
- 저자들이 중국인이여서 그런지, 수행한 실험 중 한자 손글씨 생성 task가 있어 결과를 가져와 보았습니다. 언뜻 보기엔 잘 생성된 것 같으면서도, 의미가 담긴 중요한 획이 달라지는 경우가 있는 것 같습니다. 실제 중국인들이 볼 때는 얼마정도 알아볼 수 있는지도 궁금합니다.

- LSGAN에 대한 보다 자세한 설명은 다음 링크를 참고 바랍니다.
'🌌 Deep Learning > Overview' 카테고리의 다른 글
| [StyleGAN 시리즈] ProGAN/PGGAN, StyleGAN, StyleGAN2 (0) | 2022.08.19 |
|---|---|
| [Overview] Attention 정리 - (2) seq2seq, +attention (0) | 2021.01.26 |
| [Overview] Attention 정리 - (1) LSTM (0) | 2021.01.26 |
| [Overview] YOLO 계열 Object Detection 정리 - (1) YOLO (0) | 2021.01.19 |
| [Overview] R-CNN 계열 Object Detection 정리 (Two-stage detector) (0) | 2021.01.08 |