Transformer을 구성하는 Multi-Head Self-Attention layer는 permutation equivariant한 특성을 갖기 때문에, postitional encoding이 필수적으로 필요하다.
Transformer에서 사용하는 positional encoding
우선, Transformer에서 사용하는 positional encoding의 식은 다음과 같다.
$PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$
$PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$
이를 풀어 쓰면 다음과 같은 형태를 갖게 되고,

이를 시각화하면 다음과 같다.

본 글에서는 왜 transformer의 positional encoding이 이렇게 복잡한 형태를 사용하게 됐는지를 알아보기로 한다.
Other possible methods
위의 사용한 방법 외에도 positional encoding을 수행할 수 있는 여러 가지 방법이 있다.
Method 1
가장 간단한 방법으로, 0~1 사이의 값을 이용해 일정한 비율로 position 값을 정할 수 있다.
PyTorch로는 다음과 같이 구현할 수 있다.
pos = torch.arange(max_len)/max_len

이 방법의 단점은, 문장 길이가 달라지면 각 time step 간의 차이, 즉 delta값이 달라진다는 것이다.
Method 2
두 번째 방법으로는, i번째 token의 position 값을 i로 정하는 것이다. 이 방법을 이용하면 각 time step 간 크기는 일정하지만, input의 길이가 길어지면 그만큼 position 값도 커지고, normalize되지 않은 값이기 때문에 (값이 0~1 사이가 아님) 학습이 매우 불안정해질 수 있다는 단점이 있다.

Method 3
세 번째 방법으로는, 두 번째 방법을 이진수로 표현하는 것이다. Method 2의 position value를 이진수로 표현하고, position encoding의 차원을 필요한 만큼 늘려 ($d_{model}$) scalar 값을 vector로 변환한다. 이제 position encoding은 position vector이 된다. 각 값이 0과 1 사이의 값이 되기 때문에 두 번째 방법의 문제는 사라진다.
단, 이 방법의 단점은 각 값들이 어떠한 continuous function의 이진화된 결과로 만들어진 것이 아니라, discrete function으로부터 왔다는 것이다. 따라서 interpolation 값을 얻기가 힘들다. 우리는 연속적인 함수로부터 각 position vector의 값을 얻는 방법을 찾고자 한다.

Continuous binary vector
Method 3에서 각 position 값을 이진화한 결과를 보면, 각 차원의 값들이 0과 1을 순환하며 변화한다는 것을 알 수 있다.

예를 들어, 가장 작은 bit는 한 숫자마다 0과 1이 바뀌고, 두 번째로 작은 bit는 두 숫자마다 0과 1이 바뀐다. 이러한 규칙을 통해 우리는 연속적이면서 0과 1을 순환하는 함수인 삼각함수를 생각해 볼 수 있다.
쉬운 예시로, 볼륨을 조절하는 다이얼이 있다고 하자. 각 다이얼들은 조절하는 볼륨의 크기가 다르다. 예를 들어 첫 번째 다이얼은 볼륨을 매우 미세하게, 한 칸씩 조절하고, 두 번째 다이얼은 볼륨을 두 칸씩, 세 번째 다이얼은 볼륨을 네 칸씩 조절하는 식이다. 이진법의 작동방식과 같다고 생각하면 된다. 만약 512칸이 있는 볼륨을 조절하고 싶다면, 8개의 다이얼을 이용하면 된다. 이러한 다이얼들을 이용하면 중간의 continuous한 값을 얻을 수 있다.
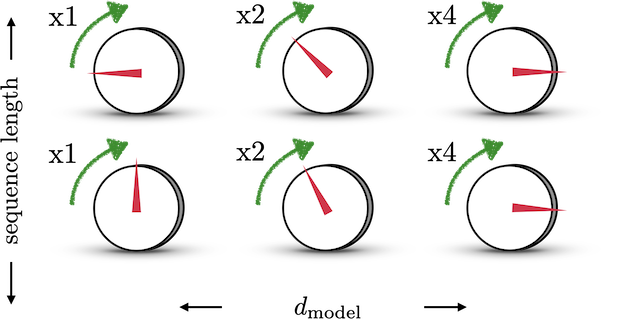
이제 이를 수식으로 나타낼 수 있다. 첫 번재 다이얼은 볼륨이 하나 커질 때마다 0<->1로 값이 바뀌고, 두 번째 다이얼은 볼륨이 두 개 커질 때마다, 세 번째 다이얼은 볼륨이 네 개 커질 때마다 바뀌어야 한다. 즉, 각 다이얼의 주기가 $\pi/2$, $\pi/4$, $\pi/8$인 sine함수를 생각할 수 있는 것이다.

따라서, 우리는 각 positional encoding tensor을 다음과 같은 matrix $M$으로 난타낼 수 있다. $i$는 각 sequence의 index를 나타내고, $j$는 position encoding의 dimension을 나타낸다고 생각하면 된다.
$M_{ij} = sin(2\pi i/2^j) = sin(x_i w_j)$
이로써 우리는 interpolation이 가능한 position encoding 방법을 찾았다. Position encoding vector의 dimension을 3이라고 했을 때 각 point를 시각화하면 다음과 같다.

Problem 1: closed curve
그럼에도 여전히 몇 가지 문제가 남아있는데, 첫 번째는 position encoding의 값들의 범위가 닫혀 있다는 것이다. 표현 가능한 마지막 position이 n이라고 할 때, 다음 수인 n+1은 첫 번째 값과 같은 position encoding 값을 갖게 되어 버린다.
이를 해결하기 위해, position encoding의 값들이 증가했다가 감소했다가 순환하는 것이 아닌, 계속 증가하게만 만든다. position encoding tensor의 식은 다음과 같이 바뀐다. 이로써 각 position encoding 값들이 boundary (-1또는 1)에 가까지 가지 않고 계속 증가하는 형태로 만들 수 있다.
$M_{ij} = sin(x_i w_0^{j/d_{model}})$
Transformer에서는 $w_0$의 값을 1/10000으로 설정하였다.
Problem 2: linearly transfromable
Position encoding을 transformer에서 이용할 때, 각 위치의 position encoding 값을 다른 위치의 position encoding 값으로 linear translation만을 통해 변환하는 것이 필요할 때가 있다.
이는 attention layer에서 이용하기 위함인데, 예를 들어 "I am going to eat" 이라는 문장이 있다고 할 때, "eat"을 번역하기 위해 "I"라는 단어에 초점을 맞추어야 하는데, 둘의 위치는 멀리 떨어져 있다. 이 때 두 단어의 position encoding이 linear transformation을 통해 변환이 가능하다면 attention을 사용하기에 보다 용이할 것이다.
각 position vector 간 linear transformation이 가능하려면 다음의 식을 만족하는 linear transformation $T(dx)$를 찾을 수 있어야 한다.
$PE(x+\Delta x) = PE(x) * T(\Delta x)$
이는 PE를 구성하는 식이 삼각함수이기 때문에 회전변환행렬을 이용하여 해결할 수 있다.

Position encoding을 변환하여 다음과 같이 구성한다면,

$T(\Delta x)$를 다음과 같이 찾을 수 있다.

출처: https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3
'🌌 Deep Learning > DL & ML 조각 지식' 카테고리의 다른 글
| [ML] Kernel Density Estimation (KDE)와 Kernel Regression (KR) (0) | 2021.10.18 |
|---|---|
| Convolution layer의 parameter 개수 (0) | 2021.10.04 |
| MSE Loss (L2 Loss) vs. MAE Loss (L1 Loss) (0) | 2021.01.19 |