CBAM: Convolutional Block Attention Module은 ECCV 2018에서 발표된 channel&spatial attention module이다. 코드는 공식 github을 참고하여 조금 수정했다.
Paper: https://arxiv.org/pdf/1807.06521.pdf
Code: https://github.com/Jongchan/attention-module/
Author's blog: https://blog.lunit.io/2018/08/30/bam-and-cbam-self-attention-modules-for-cnn/
BAM
CBAM은 BAM: Bottleneck Attention Module의 후속 논문이다. BAM은 모델의 bottleneck 부분에서 attention을 진행하는 방식으로, channel attention과 spatial attention을 병렬적으로 계산한다.

BAM에서는 channel attention과 spatial attention을 나누어 계산하고, 각 output을 더해 (+sigmoid) input size와 동일한 크기의 attention map을 생성한다. 이는 3D attention map을 두 가지 축으로 decompose했다고 볼 수 있다.
CBAM
BAM에서는 channel과 spatial attention을 따로 구해 합쳐서 final attention map을 만들었지만, CBAM에서는 channel attention을 먼저 적용한 후 spatial attention을 적용하는, 순차적인 방식을 이용했다.
주어진 input image에 대하여, channel attention module과 spatial attention module은 'what'과 'where'에 집중하는 상호보완적인 attention을 계산하게 된다.
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio, channel_attention=True, spatial_attention=True):
super(CBAM, self).__init__()
self.channel_attention, self.spatial_attention = channel_attention, spatial_attention
if channel_attention:
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio)
if spatial_attention:
self.SpatialGate = SpatialGate()
def forward(self, x):
if self.channel_attention:
x = self.ChannelGate(x)
if self.spatial_attention:
x = self.SpatialGate(x)
return x
Channel attention
BAM은 average pooling을 이용했지만, CBAM은 average pooling, max pooling 두 가지를 결합해서 사용한다. 두 pooled feature은 같은 의미를 공유하는 값이기 때문에, 하나의 shared MLP를 사용할 수 있다. (less # params)
두 attention map을 더하여 (+sigmoid) channel attention map을 생성한다.
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels),
nn.Sigmoid()
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.maxpool = nn.AdaptiveMaxPool2d((1, 1))
def forward(self, x):
x_avg_pool = self.mlp(self.avgpool(x))
x_max_pool = self.mlp(self.maxpool(x))
attention = x_avg_pool + x_max_pool
attention = attention.unsqueeze(2).unsqueeze(3).expand_as(x)
return x*attentionSpatial attention
Spatial attention 역시 channel attention과 마찬가지로, channel을 축으로 max pooling과 average pooling을 적용해 생성한 1xHxW의 두 feature map을 concat하고, 여기에 7x7 conv를 적용하여 (+sigmoid) spatial attention map을 생성한다.
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(2, 1, 7, padding=3),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
def forward(self, x):
x_avg_pool = torch.mean(x,1).unsqueeze(1)
x_max_pool = torch.max(x,1)[0].unsqueeze(1)
attention = torch.cat((x_avg_pool, x_max_pool), dim=1)
attention = self.conv(attention)
return x*attention
Results
논문에서 report한 실험 결과들이다.
Classification:
Detection:
Ablation studies
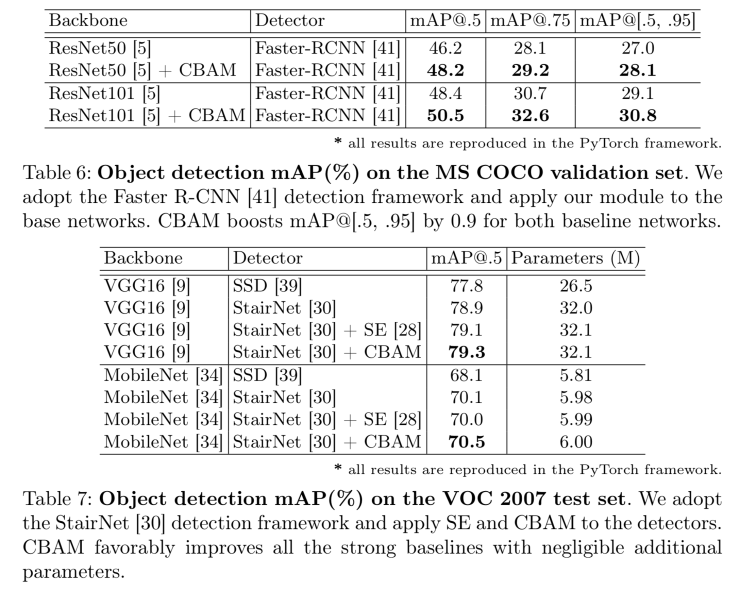
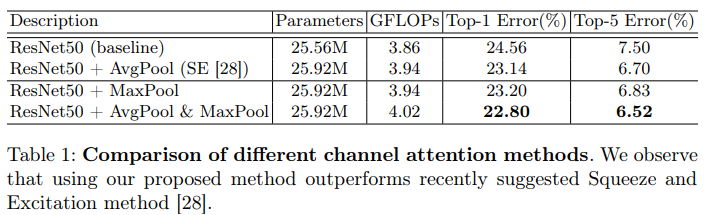
Pooling methods of channel attention:
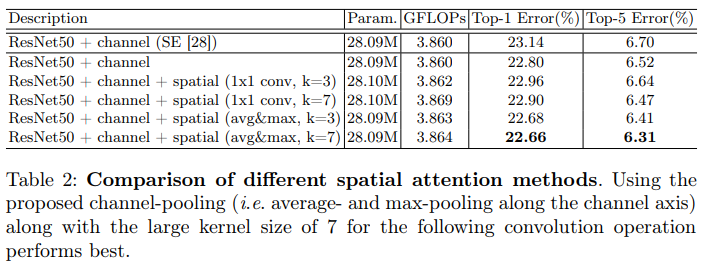
Pooling methods of spatial attention:
How to combine both channel and spatial attention modules:
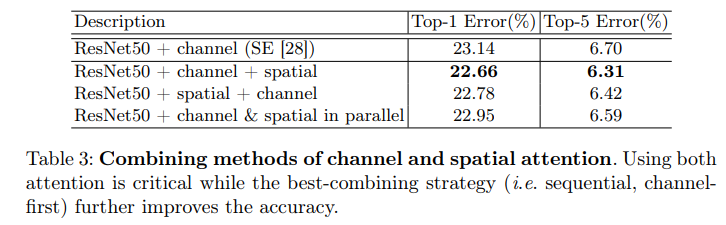
- 각 module이 서로 다른 기능을 하기 때문에, 그 순서가 전체 성능에 영향을 미칠 수 있다.
'🌌 Deep Learning > Implementation' 카테고리의 다른 글
| [PyTorch Implementation] StyleGAN2 (2) | 2022.09.26 |
|---|---|
| [PyTorch Implementation] PointNet 설명과 코드 (0) | 2022.08.12 |
| [PyTorch Implementation] ResNet-B, ResNet-C, ResNet-D, ResNet Tweaks (1) | 2022.06.05 |
| [PyTorch Implementation] PyTorch로 구현한 cycleGAN의 loss 부분 설명 (0) | 2021.08.04 |
| [PyTorch Implementation] 3D Segmentation model - VoxResNet, Attention U-Net, V-Net (0) | 2020.12.30 |