[PyTorch Implementation] StyleGAN2
StyleGAN2(Analyzing and Improving the Image Quality of StyleGAN, 2020)의 PyTorch 코드를 정리한 글. 위 Repo를 바탕으로 일부 수정했으며, 전체적인 흐름 이해를 위한 코드로, logging 등 많은 부분이 생략되어 있음.
StyleGAN 시리즈 설명: https://bo-10000.tistory.com/158
[StyleGAN 시리즈] ProGAN/PGGAN, StyleGAN, StyleGAN2
ProGAN부터 StyleGAN2까지, style transfer에서 가장 유명한 모델인 StyleGAN의 변천사와 각 모델의 특징을 간단히 정리해 보고자 한다. 1. ProGAN/PGGAN (ICLR 2018) Paper: Progressive Growing of GANs for Imp..
bo-10000.tistory.com
원본 코드 Repo: https://github.com/rosinality/stylegan2-pytorch
GitHub - rosinality/stylegan2-pytorch: Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in P
Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in PyTorch - GitHub - rosinality/stylegan2-pytorch: Implementation of Analyzing and Improving the Image Quality ...
github.com
공식 코드는 Tensorflow로 작성되었음.
GitHub - NVlabs/stylegan2: StyleGAN2 - Official TensorFlow Implementation
StyleGAN2 - Official TensorFlow Implementation. Contribute to NVlabs/stylegan2 development by creating an account on GitHub.
github.com
1. Train
- main train 코드이다. Generator, discriminator, optimizer 등을 선언하고 train 함수를 호출한다.
g_ema는 generator weight의 exponential moving average를 저장하는 모델이다. 최신 weight에 큰 가중치를 두면서 그동안의 모든 weight를 축적한다.

# modified from stylegan2-pytorch/train.py
# (https://github.com/rosinality/stylegan2-pytorch/blob/master/train.py)
def main(args):
"""
:args.iter(int,default=800000): total number of train iterations
:args.size(int,default=256): image size for model
:args.latent(int,default=512): latent size
"""
device = 'cuda'
generator = Generator(args.size, args.latent).to(device)
discriminator = Descriminator(args.size).to(device)
g_ema = Generator(args.size, args.latent).to(device) #ema: exponential moving average
g_ema.eval()
accumulate(g_ema, generator, 0)
g_optim = optim.Adam(generator.parameters(), lr=args.lr)
d_optim = optim.Adam(discriminator, parameters(), lr=args.lr)
dataset = MultiResolutionDataset(args.path, transform, args.size)
loader = data.DataLoader(dataset, args.batch_size)
train(args, loader, generator, discriminator, g_optim, d_optim, g_ema, device)- 아래는
g_ema의 exponential moving average를 위한 함수이다. 아래 함수를 통해 매 iteration마다 g_ema와 generator의 weight를 mix해서 g_ema에 저장한다.
def accumulate(model1, model2, decay=0.999):
par1 = dict(model1.named_parameters())
par2 = dict(model2.named_parameters())
for k in par1.keys():
par1[k].data.mul_(decay).add_(par2[k].data, alpha=1-decay))- 다음 함수를 통해
num_iter만큼 train iteration을 반복한다.
def train(args, loader, generator, discriminator, g_optim, d_optim, g_ema, device):
accum = 0.5 ** (32 / (10 * 1000))
for i in range(args.num_iter):
real_img = next(loader)
real_img = real_img.to(device)
#1. train discriminator
requires_grad(generator, False)
requires_grad(discriminator, True)
noise = mixing_noise(real_img.size(0), args.latent, args.mixing, device)
fake_img = generator(nose)
fake_pred = discriminator(fake_img)
real_pred = discriminator(real_img)
d_loss = d_logistic_loss(real_pred, fake_pred)
discriminator.zero_grad()
d_loss.backward()
d_optim.step()
#2. train generator
requires_grad(generator, True)
requires_grad(discriminator, False)
noise = make_noise(real_img.size(0), args.latent, device)
fake_img = generator(nosie)
fake_pred = discriminator(fake_img)
g_loss = g_nonsaturating_loss(fake_pred)
generator.zero_grad()
g_loss.backward()
g_optim.step()
accumulate(g_ema, generator, accum)requires_grad함수는 모델 parameter의 requires_grad를 False로 설정하는 역할을 한다.
def requires_grad(model, flag=True):
for p in model.parameters():
p.requires_grad = flagmake_noise: generator에 input으로 들어갈 random noise를 만든다.
def make_noise(batch, latent_dim, n_noise, device):
return torch.randn(batch, latent_dim, device=device)
2. Loss functions
위 train 코드에서 사용되는 generator loss와 discriminator loss이다. 둘 다 softplus 함수를 이용한다.
#Discriminator loss
def d_logistic_loss(real_pred, fake_pred):
real_loss = F.softplus(-real_pred)
fake_loss = F.softplus(fake_pred)
return real_loss.mean() + fake_loss.mean()
#Generator loss
def g_nonsaturating_loss(fake_pred):
loss = F.softplus(-fake_pred).mean()
return loss
3. Model
Generator과 Discriminator의 구현은 다음과 같다.
- Generator

class Generator(nn.Module):
def __init__(self, size, style_dim, n_mlp=8, channel_multiplier=2, blur_kernel=[1, 3, 3, 1], lr_mlp=0.01):
"""
:input size: img size to generate
:style_dim: latent vector size
:n_mlp: number of mlps for style mapping network
"""
super().__init__()
log_size = int(math.log(size, 2))
self.num_layers = (log_size - 2) * 2 + 1
self.n_latent = log_size * 2 - 2
channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
style = [PixelNorm()]
for _ in range(n_mlp):
style.append(EqualLinear(style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'))
self.style = nn.Sequential(*style)
in_channels = channels[4]
self.constant_input = ConstantInput(in_channels)
self.styled_conv1 = StyledConv(in_channels, in_channels, 3, style_dim, blur_kernel=blur_kernel)
self.to_rgb1 = ToRGB(sin_channels, style_dim, upsample=False)
self.styled_convs = nn.ModuleList()
self.to_rgbs = nn.ModuleList()
self.noises = nn.Module()
for layer_idx in range(self.num_layers):
res = (layer_idx + 5) // 2
shape = [1, 1, 2**res, 2**rs]
self.noises.register_buffer(f'noise_{layer_idx}', torch.randn(*shape))
for i in range(3, self.log_size+1):
out_channel = channels[2**i]
self.convs.append(StyledConv(in_channel, out_channel, 3, style_dim, upsample=True, blur_kernel=blur_kernel))
self.convs.append(StyledConv(out_channel, out_channel, 3, style_dim, blur_kernel=blur_kernel))
self.to_rgbs.append(ToRGB(out_channel, style_dim))
in_channel = out_channel
def forward(self, styles):
#1. prepare latent
styles = self.style(styles)
noise = [None] * self.num_layers
inject_index = self.n_latent
latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
#2. generator
out = self.constant_input(latent.size(0))
out = self.styled_conv1(out, latent[:, 0], noise=noise[0])
skip = self.to_rgb(out, latent[:, 1])
i = 1
for styled_conv1, styled_conv2, noise1, noise2, to_rgb in zip(
self.styled_convs[::2], self.styled_convs[1::2], noise[1::2], noise[2::2], self.to_rgbs
):
out = styled_conv1(out, latent[:, i], noise=noise1)
out = styled_conv2(out, latent[:, i + 1], noise=noise2)
skip = to_rgb(out, latent[:, i + 2], skip) #to_rgb(out) + upsample(skip)
i += 2
return skip- 주요 Generator module
class ConstantInput(nn.Module):
def __init__(self, channel, size=4):
super().__init__()
self.input = nn.Parameter(torch.randn(1, channel, size, size))
def forward(self, input):
batch = input.size(0)
out = self.input.repeat(batch, 1, 1, 1)
return out
class StyledConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, style_dim, upsample=False, blur_kernel=[1, 3, 3, 1], demodulate=True):
super().__init__()
self.conv = ModulatedConv2d(
in_channel,
out_channel,
kernel_size,
style_dim,
upsample=upsample,
blur_kernel=blur_kernel,
demodulate=demodulate,
)
self.noise = NoiseInjection()
self.activate = FusedLeakyReLU(out_channel)
def forward(self, input, style, noise=None):
out = self.conv(input, style)
out = self.noise(out, noise=noise)
out = self.activate(out)
return
class ToRGB(nn.Module):
def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
super().__init__()
if upsample:
self.upsample = Upsample(blur_kernel)
self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False) #to RGB (channel=3) via 1x1conv
self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
def forward(self, input, style, skip=None):
out = self.conv(input, style)
out = out + self.bias
if skip is not None:
skip = self.upsample(skip)
out = out + skip
return out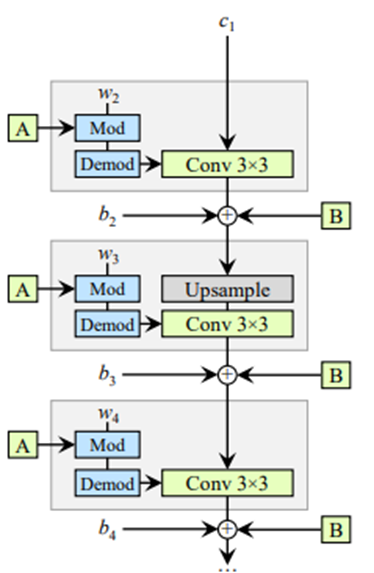
- Discriminator
class Discriminator(nn.Module):
def __init__(self, size, channel_multiplier=2, blur_kernel=[1, 3, 3, 1]):
super().__init__()
channels = {
4: 512,
8: 512,
16: 512,
32: 512,
64: 256 * channel_multiplier,
128: 128 * channel_multiplier,
256: 64 * channel_multiplier,
512: 32 * channel_multiplier,
1024: 16 * channel_multiplier,
}
convs = [ConvLayer(3, channels[size], 1)]
log_size = int(math.log(size, 2))
in_channel = channels[size]
for i in range(log_size, 2, -1):
out_channel = channels[2 ** (i - 1)]
convs.append(ResBlock(in_channel, out_channel, blur_kernel))
in_channel = out_channel
self.convs = nn.Sequential(*convs)
self.stddev_group = 4
self.stddev_feat = 1
self.final_conv = ConvLayer(in_channel + 1, channels[4], 3)
self.final_linear = nn.Sequential(
EqualLinear(channels[4] * 4 * 4, channels[4], activation="fused_lrelu"),
EqualLinear(channels[4], 1),
)
def forward(self, input):
out = self.convs(input)
batch, channel, height, width = out.shape
group = min(batch, self.stddev_group)
stddev = out.view(
group, -1, self.stddev_feat, channel // self.stddev_feat, height, width
)
stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
stddev = stddev.repeat(group, 1, height, width)
out = torch.cat([out, stddev], 1)
out = self.final_conv(out)
out = out.view(batch, -1)
out = self.final_linear(out)
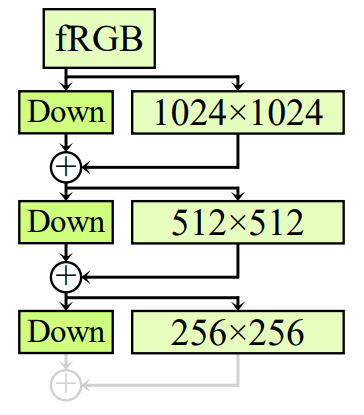
return out- 주요 Discriminator module
class ResBlock(nn.Module): #conv(input) + downsample(input)
def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
super().__init__()
self.conv1 = ConvLayer(in_channel, in_channel, 3)
self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
self.skip = ConvLayer(
in_channel, out_channel, 1, downsample=True, activate=False, bias=False
)
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
skip = self.skip(input)
out = (out + skip) / math.sqrt(2)
return out